

Chain-of-Thought(사고의 연쇄) 프롬프팅은 LLM에게 문제 해결 과정을 단계별로 설명하도록 유도하는 기법이다.
즉, 모델이 답변을 내놓기 전에 “생각”을 말하듯 중간 추론 과정을 출력하게 한다.
예를 들어 “사라가 셔츠 3장을 각각 20달러에, 청바지 2벌을 각각 50달러에 산 뒤 총액의 10% 할인을 받았다. 최종 지불액은 얼마인가?”라는 문제에 대해,
CoT 프롬프트는 “셔츠 비용: 3×20=$60; 청바지 비용: 2×50=$100; 할인 전 총액: $160; 할인액: 10%×160=$16; 최종 지불액: $160–16=$144”와 같은 중간 계산 과정을 모델이 생성하도록 한다.
이렇게 중간 과정을 명시하면 모델이 단계별 추론을 통해 더 정확한 답을 도출할 수 있다.
연구에 따르면, 복잡한 수학·상식·기호 논리 문제에서 CoT를 사용했을 때 모델의 정확도가 크게 향상된다ibm.comar5iv.org.
사실 CoT는 대규모 모델에서 출현 능력(emergent ability)으로 나타나는데, 모델 크기가 커질수록 “생각하는” 능력이 자연스럽게 향상된다ibm.comar5iv.org.
- 예시: “키워드가 홀수의 합이 짝수인가?” 같은 문제에 CoT를 적용하면, “홀수 목록: 15, 5, 13, 7, 1; 합산 결과 41; 답은 False”처럼 각 단계의 계산 과정을 보여준다. 이처럼 CoT는 모델이 논리적 단계를 생략하지 않고 설명하도록 돕는다.
- Zero-shot CoT: 때로는 예시 문장 없이 단순히 프롬프트 끝에 “… 단계별로 풀어봅시다.”를 덧붙이는 것만으로도 효과를 볼 수 있다. 예컨대 Zhou et al.의 자동화 프레임워크(AutoAPE)에서는 “올바른 답을 확인하기 위해 단계적으로 문제를 해결합시다”와 같은 지시어만으로 사람 손으로 만든 프롬프트보다 우수한 성능을 얻었다brunch.co.kr.
여러 연구에서 CoT가 가져다주는 효과가 확인되었다.
예를 들어 Wei et al.(2022)은 파라미터 540억 규모의 PaLM 모델에 CoT 예시(추론 과정을 담은 시연 예시) 8개만 제공했더니, 수학 문제 벤치마크 GSM8K에서 그때까지 최고 성능을 경신할 정도로 성능이 뛰어났다고 보고했다ar5iv.orgar5iv.org.
요약하면, Chain-of-Thought 프롬프팅은 모델에게 ‘생각’ 단계를 시각화하여 보여줌으로써 복잡한 문제 해결 능력을 획기적으로 끌어올리는 방법이다ibm.comar5iv.org.
대표 논문 요약: Wei et al., NeurIPS 2022
Wei 등(2022)의 “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” 논문은 CoT 프롬프트가 LLM의 추론 능력을 어떻게 향상시키는지 실험적으로 보여주었다ar5iv.orgar5iv.org.
이들은 세 가지 대형 LLM(파라미터 62B, 540B 등)에 CoT 예시를 제공하는 ‘few-shot CoT’ 방식을 적용해 보았다.
그 결과, 산술 문제(예: GSM8K), 상식 문제, 심볼릭 추론 문제 전반에 걸쳐 CoT 프롬프트가 표준 프롬프트보다 월등한 성능을 보였다.
특히 540B PaLM 모델은 단 8개의 CoT 예시만으로 GSM8K에서 미리 튜닝된 GPT-3+검증기(verifier) 성능을 뛰어넘었고, 정확도가 크게 향상되었다ar5iv.orgar5iv.org.
논문의 주요 내용은 다음과 같다:
- CoT의 정의: CoT는 “일련의 중간 추론 단계를 생성”하여 모델이 복잡한 문제를 해결하도록 하는 기법이다ar5iv.org.
- 실험 결과: 대규모 모델일수록 CoT 효과가 더욱 뚜렷하게 나타났다. 실험에서 62B 모델보다 540B 모델에서 CoT의 성능 향상 폭이 컸다.
- 성능 향상 예시: 연구진에 따르면 “CoT를 사용하지 않은 PaLM 540B: 정답률 55%”였던 반면, CoT를 적용하자 정확도가 57%로 올라갔다(표준 프롬프트 대비 큰 향상)ar5iv.org.
- 이론적 시사점: 모델의 크기와 훈련 데이터가 충분하면, CoT 예시만 주어도 모델이 스스로 “말하면서 생각”할 수 있게 된다는 점을 강조했다. 즉, CoT는 추가 학습 없이도 대형 모델에서 자연스럽게 출현하는 추론 능력이라는 것이다ar5iv.org.
결론적으로 Wei et al. 논문은 *“Few-shot CoT 프롬프트만으로도 LLM이 복잡한 다단계 문제를 효과적으로 풀 수 있다”*는 점을 명확히 보여주었고, 이후 CoT는 다양한 분야에서 널리 응용되기 시작했다.

문제, 풀이과정, 정답을 보여준뒤, 새로운 문제를 내주면, 그에 맞춰 풀이과정, 정답을 보여준다는 것
Tree-of-Thoughts 개념 및 CoT와의 차이점
Tree-of-Thoughts(ToT)은 CoT를 일반화한 새로운 추론 프레임워크다.
CoT가 한 가지 연속적인 추론 경로(체인)를 따르는 반면, ToT는 여러 개의 잠재적 추론 경로를 나무 구조(tree)로 탐색한다.
즉, 문제를 풀기 위해 다양한 ‘부분 해답(thoughts)’을 만들어 보고, 그 중 더 유망한 경로를 선택하면서 전체 문제 해결에 접근한다.
이 과정에서 **탐색(lookahead)**과 **백트래킹(backtracking)**과 같은 전략을 사용하여 전체적인 최적해를 찾는다.
이는 CoT가 토큰을 순차 생성(token-level)하는 한계에서 벗어나, 마치 사람이 미로를 풀 때 여러 갈래를 시도해보듯 의사결정 지점을 평가해 나가는 방식이다arxiv.org.
ToT의 특징과 CoT와의 차이점은 다음과 같다:
- 추론 구조: CoT는 한 줄(chain)의 추론을 생성하지만, ToT는 ‘생각(thought)’ 단위를 계층적 노드로 보고 여러 개의 가지(branch)를 키운다. 각 노드는 현재까지 도출된 부분 해답 상태를 나타낸다arxiv.org.
- 탐색 알고리즘: ToT는 BFS(넓이 우선 탐색), DFS(깊이 우선 탐색) 같은 고전적 탐색 기법을 활용할 수 있다. 예를 들어, 현재까지의 추론 상태들 중 가장 유망한 것을 선택해 다음 단계로 나아가거나, 유망하지 않은 경로는 버리고 다른 경로를 시도한다.
- 상태 평가: ToT는 각 중간 상태에 대해 휴리스틱(가치함수)으로 평가하여 우선순위를 매긴다. 즉, 모델이 만든 여러 후보 “생각”을 스스로 평가하여 계속 탐색할 경로를 결정한다.
- 장점: 여러 경로를 탐색하므로 한 경로에 얽매이지 않고 다양한 해법을 시도할 수 있다. 복잡한 계획, 조합 문제 등에 유리하다.
- 단점: 탐색 공간이 커지므로 계산량이 매우 많아진다. 효과적인 휴리스틱과 검색 전략 설계가 필요하다.
요약하면, CoT가 연쇄적(chain)·즉흥적 접근인 반면, ToT는 계획적(tree search)·전략적 접근이라고 볼 수 있다.
인간의 의사결정으로 비유하면, CoT는 한 가지 생각을 차례차례 떠올리는 System 1에 가깝고, ToT는 가능한 모든 가설을 저울질하며 선택하는 System 2에 가깝다.
대표 논문 요약: Yao et al., NeurIPS 2023
Yao 등(2023)의 “Tree of Thoughts: Deliberate Problem Solving with Large Language Models” 논문은 ToT 프레임워크를 제안하고 그 효과를 평가했다arxiv.orgarxiv.org.
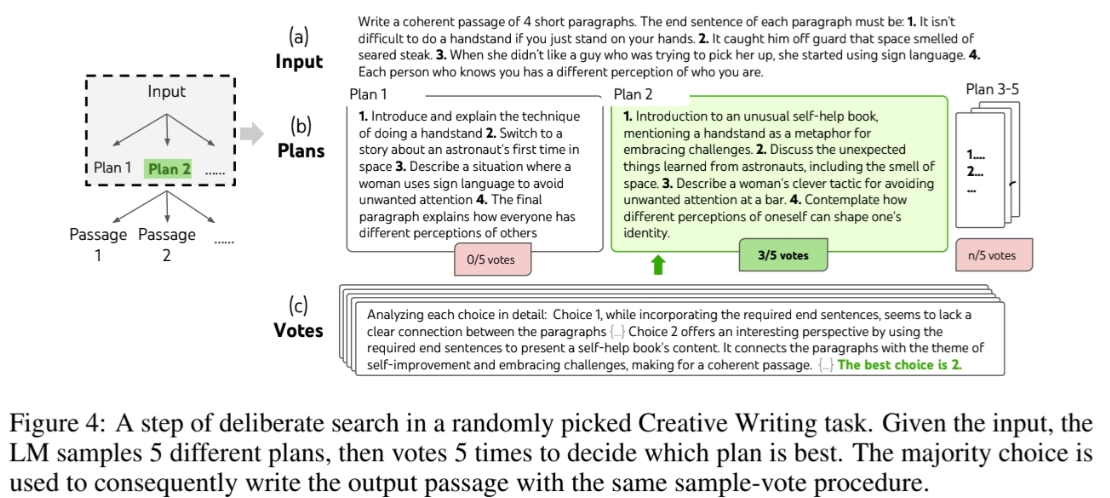
이들은 CoT로 풀기 어려운 문제를 해결할 수 있도록 설계된 세 가지 작업(게임 오브 24, 창의적 글쓰기, 미니 크로스워드)을 제시했다.
각각의 노드는 “현재 입력과 중간 생각들의 순서”로 정의되며, ToT는 아래 네 가지 요소를 포함한다arxiv.org:
- 생각(thought) 분해: 문제별로 유용한 중간 단계를 정의. 예컨대 숫자 게임에서는 한 단어, 수식 한 줄, 문단 등 다양한 크기의 생각을 정의할 수 있다arxiv.org.
- 생각 생성: 현재 상태에서 가능한 다음 “생각” 후보를 생성. 예를 들어 “다음에 어떤 수식을 사용할까?” 같은 후보들을 모델로부터 샘플링한다arxiv.orgarxiv.org.
- 상태 평가: 각 상태(노드)가 문제 해결에 얼마나 가까운지를 평가하는 휴리스틱. 모델의 점수나 투표로 판단해 유망한 경로를 선택한다arxiv.org.
- 탐색 전략: BFS나 DFS 등 다양한 검색 방법을 적용하여 트리를 확장. 중요도가 낮은 가지는 자를 수 있다arxiv.org.
실험 결과 ToT는 CoT가 거의 불가능했던 문제에서도 뛰어난 성과를 보였다.
예를 들어 숫자 조작 게임 Game of 24에서는, GPT-4에 CoT 프롬프트를 썼을 때 단지 4%의 문제만 해결했지만 ToT를 사용하자 74%까지 해결률이 올랐다arxiv.org.
이 외에도 창의적 글쓰기나 크로스워드 만들기 같은 작업에서도 ToT가 CoT를 크게 앞섰다.
논문에서는 모든 프롬프트와 코드를 공개하여 실험의 재현성을 보장했다arxiv.org.
요약하면 Yao et al. 논문은 *“하나의 사고 흐름만 고집하지 말고, 다양한 사고 과정을 탐색해라”*라는 아이디어를 구체화했다.
ToT는 대규모 언어 모델을 단일 출력기계가 아니라 탐색(search) 알고리즘과 결합해 문제를 해결하도록 만들어 주는 방법론으로서, CoT 방식의 한계를 보완한다arxiv.orgarxiv.org.

예를 들어 4개의 랜덤한 문장을 받아 4개의 단락을 만들건데, 각 단락은 각각의 문장으로 끝나야하는 TASK가 주어지
이 문제를 해결하기 위해 5개의 plan을 생성하고, 이 plan들 중 가장 좋은 plan을 찾고, 이 plan을 기반으로 5개의 output을 생성한 다음, 이 중 최적의 답을 고른다
| 구분 | Chain-of-Thought (CoT) | Tree-of-Thoughts (ToT) |
| 접근 방식 | 단일 경로 연쇄적(Sequential) 추론 | 다중 경로 트리(Branching) 탐색 |
| 추론 구조 | 입력→출력으로 바로 이어지는 문장형 추론(생각을 한 줄로 나열) | 중간 상태(node)를 가진 트리 구조. 다양한 “생각” 후보를 노드로 추가 |
| 예시 작업 | 수학 문제, 간단한 상식 추론, 일상 질문 등 | 계획 수립, 최적화 퍼즐, 게임(예: Game of 24), 창의적 문제 등 |
| 모델 요건 | 매우 큰 모델 필요(출현 능력) | 모델 크기만큼 체계적 검색+평가가 중요. 거대 모델 뿐 아니라 작은 모델에도 적용 가능 |
| 장점 | - 구현·사용이 간단하다- 계산 비용이 상대적으로 낮다- 기존 LLM 인프라 그대로 활용 | - 복잡한 문제에서 높은 성공률- 다양한 해법 시도 가능- 목표에 따른 유연한 탐색 기법 조합 |
| 단점 | - 추론 과정 오류 수정 불가(일방향적)- 잘못된 단계에 빠지면 답답해짐- 대규모 모델 필요성 | - 탐색 비용이 매우 크다- 휴리스틱 설계 필요- 구현·튜닝 난이도가 높음 |
최신 연구 동향 및 응용 사례 (2024–2025)
최근 CoT 및 ToT 기법을 발전시키기 위한 연구가 활발히 진행 중이다. 주요 트렌드는 다음과 같다:
1) Graph-of-Thoughts (GoT)
Yao et al.의 ToT를 확장하여, 사고를 그래프로 표현하는 GoT가 제안되었다arxiv.org.
GoT는 “생각” 단위를 노드로, 이들 간의 의존성을 간선으로 연결해 복잡한 네트워크 형태로 정보가 결합되도록 한다.
이를 통해 단순 계층구조를 넘어 여러 생각을 융합·반복하는 신경망적 패러다임에 가까운 추론이 가능해졌다.
실제로 GoT는 ToT에 비해 정렬 문제의 품질을 62% 향상시키고 비용은 31% 절감하는 성능을 보였다arxiv.org.
2) 자기 일관성(Self-Consistency)
Chain-of-Thought 생성 시 무작위 샘플링을 여러 번 수행하고, 다수결(consensus)을 통해 최종 답을 결정하는 기법이다(‘reason with coalitions’).
Self-Consistency를 통해 오답률을 낮추는 연구가 발표되었다(예: Wang et al. 2022, 그러나 본 답변문 예시가 2024까지 요구되므로 이론만 언급).
3) 비전-언어(Vision-Language) 추론
CoT 개념을 시각 정보 처리에 확장하는 연구가 있다.
Wu et al.(2023)은 CoT와 유사한 “설명 후 결정(Description then Decision)” 전략을 이용해 복잡한 VQA(영상질의응답) 과제의 성능을 50% 이상 향상시켰다arxiv.org.
또한 Chen et al.(2024)은 대형 멀티모달 모델의 추론 일관성이 부족함을 지적하고, LLM이 생성한 단계적 추론 예시로 비전 모델을 추가 학습시켜 성능과 일관성을 개선하는 방법을 제안했다arxiv.org.
4) 자동 CoT(Auto-CoT) 및 제로샷 CoT
수동으로 예시를 만드는 대신 모델이 스스로 유용한 CoT 예시를 생성하도록 하는 연구가 이루어졌다.
예를 들어 Amazon의 Auto-CoT 기법은 유사한 질문끼리 군집화한 뒤 각 군집 대표 질문에 대해 Zero-shot CoT로 추론 과정을 생성하여 학습시킨다.
Auto-CoT는 여러 벤치마크에서 사람이 만든 CoT 예시와 맞먹거나 더 나은 성능을 보였다learnprompting.org.
5) 사고구조 전반에 대한 분류/분석
2024년에는 CoT/ToT/GoT 등 다양한 “사고 구조(reasoning topology)” 기반 프롬프트 기법을 체계적으로 분류한 연구도 나왔다.
이 ArXiv 논문은 CoT, ToT, GoT를 포함한 여러 기법을 비교하고, 검색 알고리즘·휴리스틱·멀티모달 확장 등 다양한 설계 선택이 성능과 비용에 미치는 영향을 논의했다arxiv.org.
6) 실제 응용
이러한 기법들은 수학, 퍼즐, 계획 수립뿐 아니라 대화형 AI, 로봇 제어, 코드 생성 등 다양한 응용에 활용된다.
예를 들어 GPT-4o(vision-enabled GPT-4)에서도 체계적 출력(structured output)과 추론 강화(CoT)를 통해 복잡한 문제 해결 성능을 대폭 개선했다는 보고가 있으며, 오픈AI의 최신 모델들은 다중 샘플링·재순위 등을 활용하여 사람 수준의 수학/과학 문제 풀이 능력을 보여준다.
이처럼 최신 연구들은 기존 CoT/ToT의 성능 한계를 넘어, 다양한 추론 구조와 멀티모달 정보를 활용해 LLM을 더 똑똑한 문제 해결사로 만드는 방향으로 발전하고 있다.
'AI 논문 > AI trend research' 카테고리의 다른 글
| On the generalization of language modelsfrom in-context learning and finetuning: acontrolled study (0) | 2025.05.22 |
|---|---|
| in context learning에 대하여 학습하기 (0) | 2025.05.20 |
| RAG(Retrieval-Augmented Generation) 핵심 개념 학습하기 (0) | 2025.05.05 |
| LoRA(Low-Rank Adaptation)에 대한 개념 간단한 학습 (0) | 2025.05.04 |
| Test Time Scaling의 개념과 연구에 대한 보고서 (0) | 2025.05.03 |