


1. LoRA(Low-Rank Adaptation)이란?
LoRA는 거대한 사전학습 모델을 효율적으로 미세조정(fine-tuning)하기 위해 개발된 기법입니다.
전통적인 풀 파인튜닝에서는 모델의 모든 가중치를 업데이트해야 하지만, 모델 크기가 커질수록 계산량과 메모리 부담이 크게 늘어납니다.
예를 들어 GPT-3 175B 모델은 1750억 개의 파라미터를 전부 업데이트해야 하므로, 각각의 작업마다 별도 모델을 저장·운영하는 것이 거의 불가능합니다.
이에 LoRA는 사전학습된 가중치는 고정(freeze)한 채, 저차원 행렬을 각 Transformer 층에 추가하여 학습하는 방식을 제안합니다ar5iv.orghuggingface.co.
즉, 기존 가중치 $W^{(0)}$는 그대로 두고, 그 변화량 $\Delta W$ 만을 저차원 행렬로 표현하여 학습하는 것입니다.
LoRA를 사용하면 학습시 업데이트되는 파라미터 수가 극적으로 줄어듭니다.
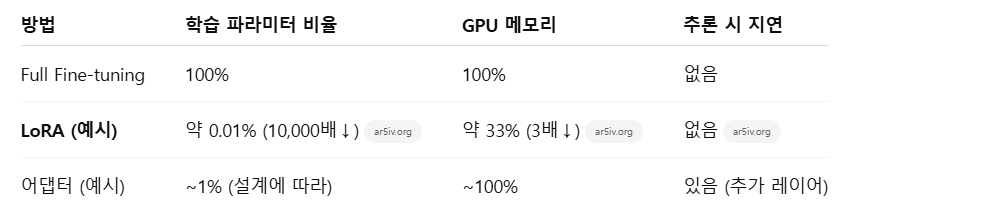
원 논문에 따르면 GPT-3 175B 모델 기준으로 학습 파라미터 수가 약 10,000배 감소하고, GPU 메모리 요구량도 3배 감소했다고 합니다ar5iv.org.
그럼에도 불구하고 성능은 풀 파인튜닝과 동등하거나 그 이상으로 나오며, 어댑터(adapter) 방식과 달리 추가적인 추론 지연(latency)도 없습니다ar5iv.orghuggingface.co.
Hugging Face의 예시에서도 총 12.3억 파라미터 모델에 LoRA를 적용하니 학습 파라미터가 약 0.19%(약 236만 개)로 줄었다고 보고되었습니다huggingface.co.
이러한 장점 덕분에 LoRA는 파라미터 효율적 파인튜닝(PEFT, Parameter-Efficient Fine-Tuning) 기법의 대표주자로 자리매김했습니다.
2. 수학적 배경: 저차원 행렬 분해 (Low-Rank Decomposition)
LoRA의 핵심은 저차원(rank) 행렬 분해입니다.
선형대수에서 임의의 크기 $n \times m$ 행렬 $W$는 랭크가 $r$인 두 행렬 $A \in \mathbb{R}^{n \times r}$, $B \in \mathbb{R}^{r \times m}$의 곱으로 분해할 수 있습니다(이를 랭크 분해라 합니다).
예를 들어 SVD(특이값 분해)를 이용하면 정확한 분해가 가능하며, 대부분의 경우 $r$을 작게 잡아도 원래 행렬을 어느 정도 근사할 수 있습니다.
이때 전체 파라미터 수는 원래 $nm$에서 **$n \cdot r + r \cdot m$**으로 줄어듭니다.
예를 들어 $W$의 크기가 $1024 \times 1024$이고 $r = 8$이라면, 학습 파라미터는 $1024 \times 8 + 8 \times 1024 = 16384$개에 불과합니다 (원래는 약 $10^6$개).
LoRA에서는 이 아이디어를 Transformer의 가중치 업데이트에 적용합니다.
구체적으로, 사전학습된 가중치 $W^{(0)} \in \mathbb{R}^{d_1 \times d_2}$에 대한 변화량 $\Delta W$를 저차원 행렬로 표현합니다.
즉, 두 작은 행렬 $A \in \mathbb{R}^{r \times d_2}$, $B \in \mathbb{R}^{d_1 \times r}$를 학습하여 다음과 같이 재파라미터화합니다:

여기서 $r$은 $d_1, d_2$보다 훨씬 작은 값으로 설정됩니다. (예: $d_1 = d_2 = 1024$일 때 $r = 8$)
학습 시 오직 $A$, $B$만 업데이트되고, $W^{(0)}$는 고정됩니다.
이렇게 하면 추가 학습 파라미터 수는 전체의 0.5% 이하로 줄어들지만, 성능은 종종 풀 파인튜닝과 유사하거나 오히려 더 좋은 결과가 나옵니다.
LoRA는 이처럼 “변화량” 행렬에 저차원 분해를 도입하여 효율적으로 큰 모델을 조정하는 방법입니다.
3. 주요 논문과 연구 동향
1) LoRA (Hu et al., 2021)
Microsoft 연구진이 제안한 원 논문ar5iv.org입니다.
Transformer 각 층의 가중치를 고정한 채, 저차원 분해 행렬을 삽입하여 파인튜닝 비용을 대폭 줄였습니다.
GPT-3, GPT-2, RoBERTa 등 다양한 모델에서 실험하여 품질을 유지하면서 학습 파라미터를 10000배 이상 줄이고 메모리도 3배 절감했다고 보고했습니다.
또한 추론 지연이 없고, GLUE 벤치마크 등 여러 자연어 처리 과제에서도 뛰어난 성능을 보여주었습니다ar5iv.orgar5iv.org.
2) QLoRA (Dettmers et al., 2023)
LoRA를 4비트 양자화(Quantization) 모델에 적용한 기법입니다arxiv.org.
사전학습 모델을 4비트 정밀도로 양자화한 상태에서 역전파를 수행하고, 저차원 LoRA 어댑터를 학습합니다.
이 덕분에 65B급 모델도 단일 48GB GPU로 미세조정할 수 있게 되었고, 최종 결과는 16비트 파인튜닝과 유사한 품질을 유지했습니다arxiv.org.
대표 모델 “Guanaco” 시리즈는 GPT-3 대비 99.3% 수준의 성능을 단 24시간 학습으로 달성했습니다.
3) AdaLoRA (Zhang et al., ICLR 2023)
학습 중에 각 행렬의 랭크를 동적으로 조정하는 방법론입니다arxiv.org.
기존 LoRA는 모든 가중치에 동일한 랭크 r를 적용했으나, AdaLoRA는 중요도가 높은 가중치에 더 많은 랭크(파라미터)를 할당합니다.
중요도가 낮은 축에는 랭크를 줄여 파라미터 예산을 절약하고, 성능을 개선합니다arxiv.org.
4) LoRA-C (Ding et al., 2024)
Transformer가 아닌 **합성곱 신경망(CNN)**에 LoRA를 적용한 연구입니다arxiv.org.
IoT 장치용으로 제안된 이 방법은 합성곱 계층 단위로 저차원 분해를 수행해, 표준 ResNet 대비 파인튜닝 파라미터 수를 99% 이상 줄이면서도 노이즈 환경에서의 정확도를 크게 향상시켰습니다arxiv.org.
CNN 등 비(非) Transformer 모델에도 LoRA 확장이 가능함을 보여줍니다.
5) 기타 PEFT 기법
어댑터(Adapter, Houlsby et al.), 프롬프트 튜닝(Prompt/Prefix Tuning), BitFit 등 다양한 효율적 파인튜닝 기법이 있습니다.
LoRA는 어댑터와 달리 추론 시 추가 레이어를 사용하지 않아 지연이 없고, 프롬프트 튜닝보다 모든 토큰 레이어에 적용 가능하다는 장점이 있습니다.
4. 실제 적용 사례
1) 자연어 처리(NLP)
LoRA는 BERT, RoBERTa, DeBERTa 같은 분류·이해 모델부터 GPT-2/3 같은 생성 모델까지 광범위한 NLP 과제에 적용됩니다.
원 논문에서는 GLUE 벤치마크(자연어 이해)와 위키 SQL 생성, 대화문 요약(SAMSum) 같은 자연어 생성 과제에서 LoRA 성능을 테스트했습니다ar5iv.org.
예를 들어 RoBERTa/DeBERTa 기반 모델을 다양한 분류·NLI 과제에, GPT-2를 문장 생성·질의응답에 활용하여 풀 파인튜닝과 대등한 품질을 확인했습니다.
즉, 텍스트 분류, 번역, 요약, 질의응답 등 대부분의 NLP 도메인에서 LoRA를 활용할 수 있습니다.
2) 이미지 생성 및 비전 모델
Hugging Face와 커뮤니티는 Stable Diffusion 같은 대형 이미지 생성 모델에 LoRA를 적용하는 방법을 선보였습니다huggingface.co.
Stable Diffusion의 경우 이미지 표현과 프롬프트(텍스트) 간 연관을 학습하는 크로스 어텐션 레이어에 LoRA를 삽입합니다.
이를 통해 몇 장의 예시 이미지로도 특정 스타일이나 사물을 효과적으로 학습시켜 새로운 이미지를 생성할 수 있습니다.
실제로 LoRA를 이용한 DreamBooth 기법은 적은 데이터/리소스로도 만족할 만한 고품질 이미지를 생성하며, 모델을 빠르게 ‘전문화’시킬 수 있습니다.
3) 코드 예제 (Hugging Face PEFT 라이브러리)
실전에서는 Hugging Face의 PEFT 라이브러리를 이용해 간단히 LoRA를 적용할 수 있습니다.
예를 들어 Seq2Seq 모델에 LoRA를 적용하려면 아래와 같은 절차를 따릅니다huggingface.co:
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_model, LoraConfig, TaskType
model_name = "bigscience/mt0-large"
# LoRA 설정: r=8, alpha=32 등
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# 출력 예: trainable params: 2359296, all params: 1231940608 (약 0.19%)
위 예시에서 보듯, get_peft_model으로 모델을 래핑하면 지정한 rank(r)만큼의 추가 행렬만 학습됩니다.
결과적으로 전체 파라미터(12.3억개)의 0.19%만 업데이트되어 훨씬 적은 메모리와 계산량으로 학습이 가능합니다huggingface.co.
4) 기타 응용
LoRA는 LLM 기반 챗봇, 지식 추출 모델, 추천 시스템 등에서도 응용됩니다.
또한 CNN 모델(예: ResNet)에서도 LoRA-C 같은 방식으로 채택 가능해, IoT나 모바일 같은 자원제한 환경에서도 파인튜닝 부담을 줄여 줍니다arxiv.org.
5. 장단점 및 한계
1) 장점
- 파라미터 효율성: 학습할 파라미터 수가 극히 작아 계산·메모리 비용이 대폭 절감됩니다ar5iv.orgarxiv.org. 예를 들어 1조 개 파라미터 모델도 수백만 개만 학습하면 됩니다.
- 성능 유지: 많은 작업에서 풀 파인튜닝과 거의 동등한 성능을 내며, 때로는 GPT-4보다 우수한 결과를 내기도 합니다anyscale.com. 특히 SQL 생성 등 특정 도메인에서는 LoRA가 더 좋은 성능을 보였습니다anyscale.com.
- 빠른 전환: 하나의 사전학습 모델에 여러 태스크용 LoRA 모듈을 붙여 사용하면, 작업 간 전환이 쉽고 스토리지도 효율적입니다. 실제로 LoRA로 생성된 체크포인트 크기가 매우 작아(몇 MB 수준) 여러 모델을 한 번에 관리하기 유리합니다anyscale.com.
- 추론 오버헤드 없음: 추가 레이어를 삽입하지 않기 때문에 어댑터와 달리 추론 속도 저하가 없습니다ar5iv.org. 학습한 LoRA 행렬을 기본 가중치에 병합하면 일반 모델과 동일하게 추론할 수 있습니다.
2) 단점/한계
- 모델 품질 감소 가능성: 모델에 따라 일부 작업에서 품질 저하가 생길 수 있습니다. 실제 사례에서는 LoRA가 특화된 작업에서는 훌륭했지만, 수학적 추론이나 범용적인 지식이 필요한 과제에서는 약간 떨어지는 경향이 관찰되었습니다anyscale.com. 따라서 중요한 경우에는 rank나 하이퍼파라미터를 조절하면서 성능을 검증해야 합니다.
- 다중 작업 처리 어려움: 서로 다른 작업별로 LoRA 모듈을 별도로 관리해야 하므로, **배치(batch)**로 서로 다른 태스크를 함께 처리할 때 제약이 있습니다ar5iv.org. LoRA 행렬을 기본 가중치에 병합(merge)하면 속도는 빨라지지만 다중모델 관리가 힘들고, 병합하지 않으면 추론 코드가 복잡해집니다ar5iv.org.
- 하이퍼파라미터 민감도: 랭크 r, 학습률, 스케일링 상수(α) 등의 값을 적절히 설정해야 합니다. 랭크를 너무 작게 잡으면 표현력이 부족하고, 너무 크게 잡으면 효율성이 떨어집니다.
- 적용 범위: 기본적으로 선형 계층(주로 어텐션·FFN 가중치)에 적용하며, CNN이나 임베딩 등 비표준 구조는 별도 연구(LoRA-C 등)가 필요합니다. 예를 들어 Vision Transformer 이외의 CNN에서는 추가 기법이 요구될 수 있습니다arxiv.org.
요약하면, LoRA는 대형 모델 미세조정을 매우 효율적으로 해주는 강력한 도구입니다.
적절히 활용하면 단기간·저비용으로 고성능 결과를 얻을 수 있지만, 모든 상황에서 완벽하지는 않습니다.
특히 다중태스크 환경이나 매우 복잡한 문제에 대해선 주의가 필요하며, 후속 연구(Adaptive LoRA, Rank-adaptive LoRA 등)가 계속 나오고 있습니다.
그럼에도 불구하고 LoRA 덕분에 수백억~조 단위 모델을 몇 장의 GPU에서 실용적으로 다룰 수 있게 되었다는 점은 매우 획기적인 발전입니다ar5iv.organyscale.com.
---------------------------------------------------------------------------------------------------------------------------------------------------------
대충 이런 느낌인듯?
사전학습된 모델의 가중치 $W^{(0)}$를 불러와서 이 가중치는 고정하고,
일부 layer의 가중치 $\Delta W = BA$를 학습해서 기존의 transformer layer에 더해주는 개념이라는데?
LoRA는 기존 pre-trained weight는 고정하고, 몇 개의 dense layer만 rank decomposition matrices를 최적화하는 방식으로 학습시키기로 함.
기존 pre-trained weight 는 고정하고 low rank decomposition된 weight 만 학습시켜 에 더해줌.
이런 느낌이라는데?
원 논문을 한번 읽어보는게 좋을지도
'AI 논문 > AI trend research' 카테고리의 다른 글
| Chain-of-Thought Prompting 개념 학습하기 (0) | 2025.05.06 |
|---|---|
| RAG(Retrieval-Augmented Generation) 핵심 개념 학습하기 (0) | 2025.05.05 |
| Test Time Scaling의 개념과 연구에 대한 보고서 (0) | 2025.05.03 |
| Why do LLMs attend to the first token? (0) | 2025.04.15 |
| Model Context Protocol(MCP) 개념 이해하기 (0) | 2025.04.01 |