


1. 개념 소개 및 등장 배경
대규모 사전학습 언어 모델(LLM)은 방대한 지식을 파라미터에 내장하지만, 지식집약형 작업에서는 정확한 정보 접근과 조작에 한계가 있습니다ar5iv.org.
예를 들어 RAG(2020) 논문에서는 사전학습된 시퀀스-투-시퀀스(seq2seq) 모델(파라메트릭 메모리)과 위키피디아 지문을 색인한 밀집 검색(DPR) 모듈(비파라메트릭 메모리)을 결합하여, 입력 질문에 관련 문서를 검색한 후 이를 컨텍스트로 답변을 생성한다고 소개합니다ar5iv.orgarxiv.org.
이렇게 함으로써 기존 모델보다 질의응답 정확도를 크게 높이고, 생성한 답변의 구체성과 사실성도 개선할 수 있었습니다arxiv.orgar5iv.org.
RAG는 특히 답변 근거 제시(provenance)와 지식 업데이트라는 한계를 개선하고자 고안된 기술입니다.
2. 기술적 구조와 작동 원리
RAG의 기본 구조는 **검색기(Retriever)**와 **생성기(Generator)**의 두 단계로 구성됩니다.
사용자가 질문을 입력하면 우선 검색기가 질문 쿼리(q)와 미리 색인된 문서 집합을 비교하여 가장 관련성 높은 상위-K개 문서(비파라메트릭 메모리)를 찾아옵니다.
그런 다음 생성기(예: BART, T5)는 원본 질문과 검색된 문서들을 입력으로 받아 답변을 생성합니다

그림: RAG 시스템의 개념적 구조. 좌측은 쿼리 생성 후 검색 모델을 통해 관련 문서를 찾아오는 과정, 우측은 검색 결과를 활용해 생성 모델이 답변을 생성하는 과정입니다.
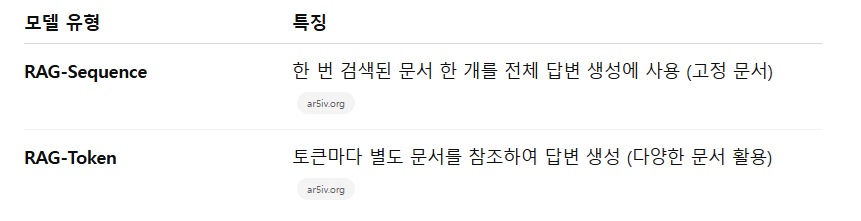
생성 과정에서는 두 가지 방식이 있습니다.
RAG-Sequence는 하나의 검색된 문서를 선택하여 전체 답변을 만드는 반면, RAG-Token은 각 출력 토큰마다 다른 문서를 참조하며 답변을 생성합니다ar5iv.orgar5iv.org.
이 두 방식의 특징을 비교하면 다음과 같습니다:
이 과정을 수식적으로는 검색된 문서를 잠재 변수(latent variable)로 보고, 이 변수를 문서별로 주변화(marginalize)하여 최종 답변 확률을 계산합니다ar5iv.org.
3. 핵심 논문 요약
1) RAG (2020, Lewis et al.)
Facebook AI 연구진의 RAG 논문은 조합된 메모리 모델을 제안했습니다.
DPR(Dense passage retriever)로 질문과 유사한 상위-K개 위키 문서를 검색하고, BART/T5 기반 생성 모델에 이 문서들을 추가 컨텍스트로 제공하여 답변을 만듭니다.
저자들은 전체 문장을 한 문서로 생성하는 RAG-Sequence와 토큰별로 다른 문서를 선택하는 RAG-Token 두 가지 변형을 소개했고, 여러 공개 QA 벤치마크에서 기존 방법보다 높은 성능을 달성했다고 보고했습니다arxiv.orgar5iv.org.
2) REALM (2020, Guu et al.)
구글의 REALM은 사전학습 단계부터 문서 검색을 활용하는 접근입니다.
LLM의 학습 시점에 백엔드로 위키피디아 같은 대규모 텍스트 코퍼스를 두고, 마스킹된 언어 모델링 과정에서 필요한 정보는 검색기(retriever)를 통해 가져와 학습합니다.
이 방식으로 학습된 모델은 Open-QA 파인튜닝 시 기존 모델 대비 정확도를 4~16% 높였으며, 추론 과정에서 근거 문서를 함께 제공할 수 있습니다arxiv.org.
3) Atlas (2022, Borgeaud et al.)
구글 연구진이 제안한 Atlas는 Fusion-in-Decoder(FiD) 아키텍처를 활용한 RAG의 확장판입니다.
대규모 LLM과 검색기를 동시 학습(pre-training)하여, 소규모 모델임에도 불구하고 답변 품질을 크게 높였습니다.
예를 들어 11B Atlas 모델은 단 64개의 학습 예시로도 540B 파람의 PaLM보다 더 높은 오픈 도메인 QA 정확도를 기록했습니다arxiv.org.
4) RAG 2.0 (2024)
Contextual AI 팀이 제안한 개념으로, 기존 RAG가 사전학습된 부품을 조합해 사용하는 반면, RAG 2.0은 검색기와 생성기를 단일 시스템으로 통합학습합니다.
즉, 도메인 특화된 데이터 위에서 검색기와 LLM을 함께 fine-tuning하여, 엔터프라이즈 용도로 더욱 견고하고 일관성 있는 성능을 낼 수 있게 합니다contextual.aicontextual.ai.
Contextual AI는 이를 통해 GPT-4 기반 RAG보다 높은 벤치마크 성능을 달성했다고 주장합니다.
4. 최신 연구 동향 및 산업 적용 사례
최근 대형 언어 모델의 실무 도입이 늘어나면서 RAG도 산업계에서 주목받고 있습니다.
예를 들어 기업용 AI 어시스턴트 구축 시 약 2024년 말 기준 30~60% 이상의 프로젝트가 RAG를 활용해 내부 지식을 안전하게 결합하는 것으로 추정됩니다medium.com.
마이크로소프트의 Bing Chat이 웹검색 결과를 RAG 방식으로 LLM에 제공하고 있으며, 금융업체 모건스탠리의 GPT-4 어드바이저도 사내 데이터베이스를 검색하는 RAG 기반 시스템입니다medium.com.
이처럼 최신 응용에서는 RAG를 통해 생성 답변의 출처 제공과 데이터 보안 유지가 가능해집니다.
학계 및 업계에서는 RAG 성능을 높이기 위한 다양한 변형 기법도 등장했습니다.
예를 들어 Adaptive RAG나 Graph RAG처럼 검색기와 LLM을 함께 최적화하는 연구가 진행 중이며, HyDE(Hypothetical Document Embeddings) 기법처럼 LLM으로 생성한 가상 답변 문서를 기반으로 검색 정확도를 높이는 방법도 제안되었습니다zilliz.com.
HyDE는 GPT-3.5로 질문에 대한 가상의 답변을 생성하고 그 임베딩으로 유사 문서를 검색하는 방식으로, 제약 없는 제로샷 검색을 가능하게 합니다zilliz.com.
이 밖에도 Dynaprompt, RePlug 같은 모델들은 검색기-생성기 간의 피드백을 활용해 정확도를 개선합니다.
5. 관련 기술 및 유사 아키텍처 비교
RAG와 유사한 개념을 활용하는 기술로는 여러 예가 있습니다.
먼저 OpenAI ChatGPT Retrieval Plugin은 RAG 아이디어를 활용해 사용자가 보유한 문서 또는 데이터베이스를 벡터 스토어로 등록하고, 이를 검색해 ChatGPT 대화에 활용합니다.
이 플러그인은 사용자가 자신의 문서 내에서 자연어 질의를 통해 관련 스니펫을 얻도록 돕고, 검색된 결과를 세션(context)에 추가하여 답변의 정확도를 높입니다openai.comopenai.com.
또한 앞서 언급한 HyDE는 전통적인 문서 검색과 반대로 질문에 대한 가상 문서를 생성해 검색에 활용한다는 점이 독특합니다zilliz.com.
그 외에도 Google의 REALM, DeepMind의 RETRO(Large Language Retrieval) 등도 RAG과 맥락이 비슷한 기법으로, 대형 모델 학습 및 추론 과정에 외부 지식을 모듈 형태로 결합합니다.
Fusion-in-Decoder(FiD) 방식도 관련 기술로, 검색된 여러 문서를 디코더에서 병합하여 한 번에 처리하는 접근으로 RAG와 유사한 역할을 합니다.
6. 실습 예제 (Hugging Face)
실제 구현에서는 Hugging Face의 RagRetriever, RagSequenceForGeneration/RagTokenForGeneration 클래스를 통해 간단히 사용할 수 있습니다huggingface.co.
Hugging Face Transformers 라이브러리에는 RAG 사용을 위한 클래스들이 포함되어 있어, 손쉽게 RAG 파이프라인을 구현할 수 있습니다huggingface.co.
예를 들어 facebook/rag-sequence-nq 사전학습 모델로 검색기와 생성기를 초기화하고 질문에 답하는 코드 예시는 다음과 같습니다:
샘플 색인을 사용하여 간단히 RAG 모델을 구동하는 예시입니다.
실제 응용 시에는 벡터 데이터베이스(예: FAISS, Milvus, Pinecone 등)에 더 큰 문서 집합을 색인해 사용할 수 있습니다.
!pip install datasets
!pip install faiss-cpu
from datasets import load_dataset
import faiss
from transformers import RagSequenceForGeneration, RagTokenizer, RagRetriever
# 토크나이저, 검색기, 모델 초기화 (샘플 위키 색인 사용)
tokenizer = RagTokenizer.from_pretrained("facebook/rag-sequence-nq")
retriever = RagRetriever.from_pretrained(
"facebook/rag-sequence-nq", index_name="compressed", dataset="wiki_dpr"
)
model = RagSequenceForGeneration.from_pretrained(
"facebook/rag-sequence-nq", retriever=retriever
)
# 질문을 입력으로 답변 생성
question = "What is the capital of France?"
inputs = tokenizer(question, return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"])
answer = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
print(answer) # 예상 출력: "Paris"
용량이 너무 많이 들어서 써볼수가 없는..
일반적인 LLM과는 차이점이 model.generate할때 retriever에서 다운받은 문서를 검색해서 정답을 내는듯?
'AI 논문 > AI trend research' 카테고리의 다른 글
| in context learning에 대하여 학습하기 (0) | 2025.05.20 |
|---|---|
| Chain-of-Thought Prompting 개념 학습하기 (0) | 2025.05.06 |
| LoRA(Low-Rank Adaptation)에 대한 개념 간단한 학습 (0) | 2025.05.04 |
| Test Time Scaling의 개념과 연구에 대한 보고서 (0) | 2025.05.03 |
| Why do LLMs attend to the first token? (0) | 2025.04.15 |