

1. 2012 AlexNet
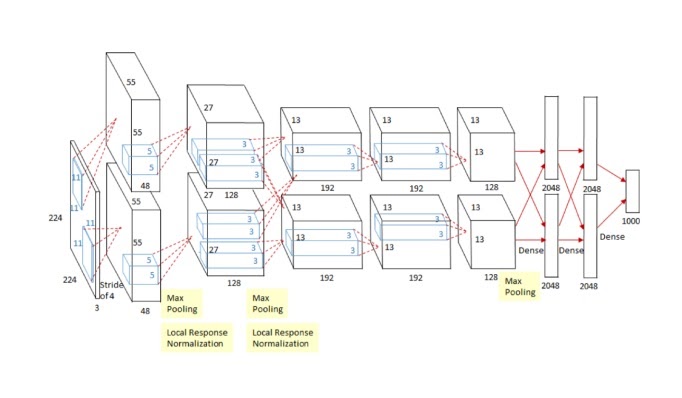
AlexNet 이전에는 고전적인 svm 등이 대회에서 1등을 했으나
AlexNet 이후 딥러닝 모델이 대회 1등을 놓친 적이 없다
224*224 이미지를 분류하는 CNN
왜 잘되는지 모르겠지만
인간을 모방한다니까 잘될 것 같다던 막연한 믿음의 유망주 딥러닝이 실제 성능을 발휘한 계기
2. 2013 DQN

딥마인드가 처음 개발한 알고리즘
그림에서 보이는 아타리 게임을 인간 수준으로 플레이할 수 있는 강화학습 알고리즘
아무것도 알려주지 않고 마음대로 플레이하게 놔두면,
처음엔 버벅거리다가 점점 스스로 게임을 이해하여 공략법을 익히고 실제로는 고수의 플레이를 보여준다
이후 딥마인드는 구글에 인수되어 알파고를 개발하였다
3. 2014 encoder/decoder

언어를 번역하는 아이디어인데 NLP문제의 트렌드를 바꾼 아이디어이다
다시보니까 왜 획기적인지 알겠다
그동안 RNN이 문장을 전부 보지않고 생성물을 내놓았다면
ENCODER와 DECODER의 탄생으로 문장을 전부 이해한 뒤에 생성물을 내놓았다는 사실이 획기적인 아이디어
4. 2014 adam optimizer

SGD에서 파생된 최적화기법인데 그냥 웬만하면 결과가 잘되니까 가장 유명하다
5. 2015 GAN

딥러닝 역사의 한 획을 그은 아주 중요한 이론?
네트워크는 Generator와 discriminator 2개를 합쳐서 학습한다?
generator가 주어진 이미지와 비슷한 이미지를 만들어내고
discriminator가 이것이 generator가 만든 이미지인지 실제 이미지인지 구별하게 된다
generator는 discriminator가 구별하지 못하도록 실제와 아주 비슷한 이미지를 만들려고 노력하게 된다
반대로 discriminator는 어떻게든 구별하려고 노력하는것
6. 2015 ResNet
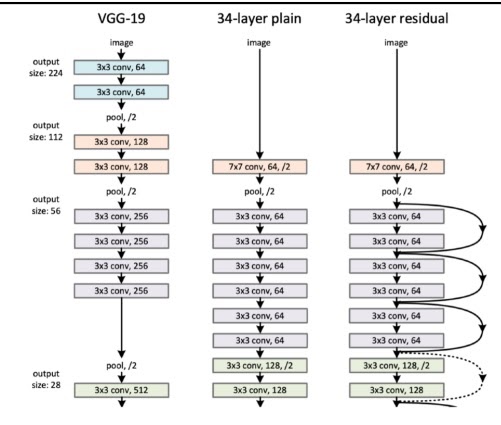
기존에는 20단정도가 깊은 네트워크의 한계라고 생각했음
네트워크는 너무 깊으면 깊을수록 학습 성능은 좋아도 테스트에서 성능은 안좋았다
ResNet 이후 100단정도까지도 커버할정도로 딥러닝이 발전함
7. 2017 transformer
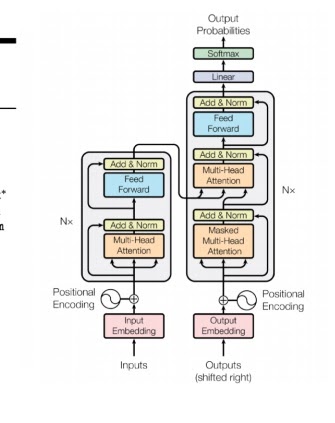
당시에는 큰 주목을 받은 것은 아니지만
지금와서 보니 RNN을 전부 대체할 정도로 중요한 아이디어
8. 2018 BERT
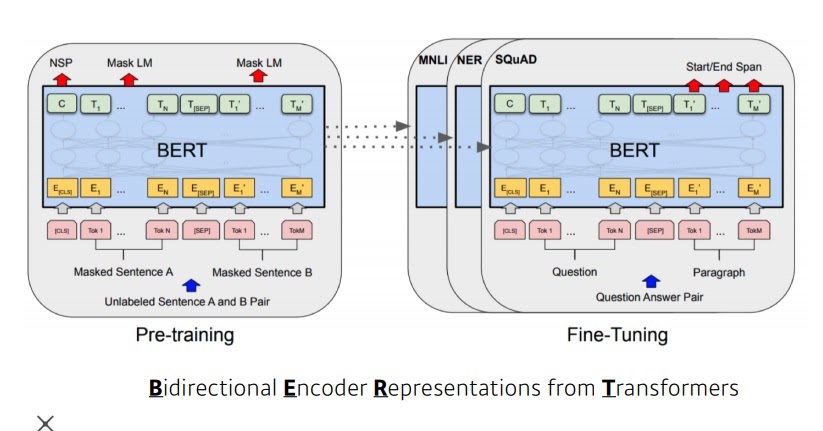
NLP 문제에서 미리 훈련한 Pre trained 모델로부터 fine-tuned 모델을 구해 성능을 높이는 전략?
9. 2019 big language model

모수가 미친듯이 많은 Fine tuned NLP 모델의 끝판왕들 등장
이후 NLP의 기본 전략은 모수가 많은 괴물 모델을 pretrain시키고 이를 주어진 task에 fine-tuning시키는 전략이 된다.
10. 2020 self supervised learning
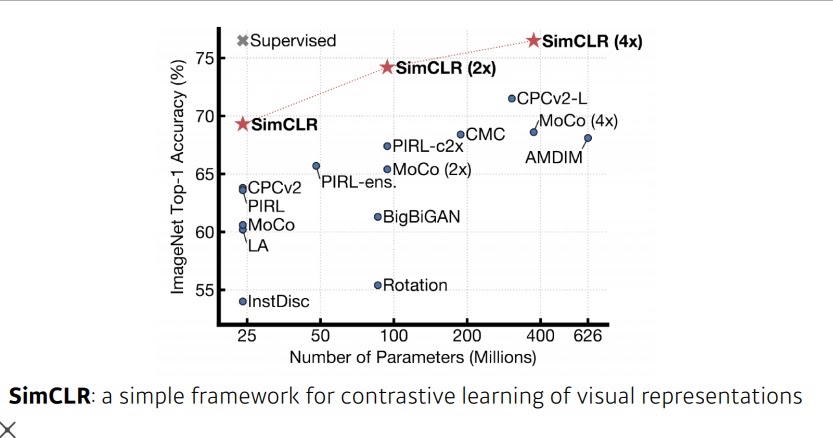
한정된 학습데이터로 여러 Parameter을 조절하여 모델을 만드는 기존의 방식에서
주어진 학습데이터 외에 unsupervised된 좋은 데이터도 학습시키겠다는 전략
심지어 학습데이터를 잘 아는 모형이 스스로 비슷한 데이터를 만들어서 학습하는 전략도 연구
'딥러닝 > 딥러닝 기초' 카테고리의 다른 글
| transfer learning이란 무엇일까? (0) | 2022.02.09 |
|---|---|
| 유사도(similarity)와 거리(distance)는 무슨 차이가 있을까?(+ cosine distance vs. euclidean distance) (0) | 2022.02.07 |
| convolution 연산의 stride와 padding (0) | 2022.02.04 |
| convolution 연산 이해하기 중급편 (0) | 2022.02.03 |
| convolution 연산 이해하기 기본편 (0) | 2022.02.01 |