

1. cross validation의 목적
과적합을 피하고 parameter를 튜닝하면서 일반적인 더욱 신뢰성있는 모델을 만들기 위해서이다.
2. holdout validation - validation set이 왜 필요할까?-
validation set은 왜 필요한가?
일반적으로 train set과 test set을 7:3의 비율로 나누는데 그런 경우 train한 모델이 train set에만 과적합될 가능성이 매우 높다.

그래서 train set을 train과 validation set으로 나누는데
이 경우 validation set으로 train model을 평가하면서 hyperparameter를 튜닝할 수 있게 된다.

이렇게 데이터셋을 나누는 것을 holdout validation이라 한다.
그런데 이 경우에도 여전히 문제점은 validation set에 과적합될 가능성이 높다는 것이다.
당연한 것이 validation set에 맞춰 hyperparameter를 튜닝하니까 그렇다
그래서 여러번의 검증을 수행하고자 다양한 방법이 제시되었다.
3. k-fold cross validation

train set을 k subset으로 나눠서 k-1개 set을 train set으로 하고 나머지 1개를 validation set으로 만드는 방법이다.
중요한 점은 k fold 마다 위 그림과 같이 validation, train 구성을 다르게 한다는 점이다.
각 fold의 결과를 평균을 내어 최종적인 성능을 구한다.
다양한 validation set에 맞춰 hyperparameter 튜닝을 하기 때문에 하나의 validation set에 맞춰진 학습을 피할 수 있다.
일반적으로 k=5나 k=10이 성능이 좋다고 알려져있다
4. repeated k fold cross validation
k fold cross validation이 data set을 랜덤하게 k개로 split하므로
이러한 랜덤성을 고려하여 k fold cross validation을 n번 반복하여 랜덤성을 피하고자 고안된 방법이다.
5. stratified k fold cross validation
일반적으로 class 분류문제에서 자주 사용하는 방법
전체 데이터에서 각 class에 속하는 데이터의 비율이 split된 data set들에 동일하게 들어가게 만들고 싶은 것
하나의 set에 특정 클래스가 과하게 분포되는 것을 막고 싶은 것임
6. leave one out cross validation
데이터가 n개라면 1개는 놔두고 n-1개만 가지고 train을 시키고 남은 1개로 test하는 방법이다.
이 과정을 반복하면 n번 할 수 있겠지
여기서 n set가 아니고 진짜로 n개, 1개, 개수를 말한다
말 그대로 1set가 아니고 진짜로 1개만 가지고 평가한다
당연하지만 n이 매우 크면 시간이 오래 걸릴 것
그래서 데이터 수가 적을 때 꽤 효과적이다.
참고로 평가용 set이 p개이면 leave p-out cross validation이라고 부른다.
p=1이니까 leave one out cross validation이 된다.
7. repeated random sub sampling validation
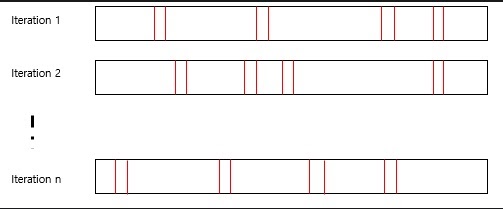
각 iteration마다 dataset에서 임의로 적절한 validation set을 선정하는 방법
조금만 생각해보면 k-fold cross validation보다 더 랜덤하게 validation을 선정한다는 것을 알 수 있다.
당연하지만 모든 반복이 끝나더라도 validation set으로 선택되지 않는 데이터가 존재할 수도 있다.
8. nested cross validation

k-fold cross validation처럼 k개의 fold를 구성하는데 k-1개의 train set과 나머지 1개는 test set으로 구성한다.
이것을 outer loop라고 한다.
그러면 이제 각 fold에 존재하는 k-1개의 train set으로 training을 시킬 것인데
그러면 각 train set마다 validation을 수행할 수 있다
즉 각 fold의 k-1개의 train set을 가지고 각각 k’-fold cross validation을 실시한다. 이것을 inner loop라고 한다.
여기서는 이제 k’-1개의 train set과 1개의 validation set으로 나눠서 실시한다
한 fold에서 k’-fold cross validation이 끝났으면 test set으로 평가하고 다음 fold로 반복 진행한다.
결과는 좋겠지만 당연히 시간이 엄청 오래걸릴것
9. 참고
https://blog.naver.com/PostView.nhn?blogId=winddori2002&logNo=221850530979
[바람돌이/머신러닝] 교차검증(CV), Cross Validation, K-fold, TimeSeries 등 CV 종류 및 이론
안녕하세요. 오늘은 머신러닝에서 정말 많이 사용되는 교차검증(Cross Validation)에 대해서 정리하겠습...
blog.naver.com
https://juni5184.tistory.com/14
Cross validation 종류
Cross Validation 종류 1. K-fold Cross-validation 데이터셋을 K개의 sub-set으로 분리하는 방법 분리된 K개의 sub-set중 하나만 제외한 K-1개의 sub-sets를 training set으로 이용하여 K개의 모..
juni5184.tistory.com
'딥러닝 > 딥러닝 기초' 카테고리의 다른 글
| convolution 연산 이해하기 기본편 (0) | 2022.02.01 |
|---|---|
| backpropagation의 개괄적인 설명 (0) | 2022.01.26 |
| 확률적 경사하강법(stochastic gradient descent method) (0) | 2022.01.04 |
| cross validation이란? (0) | 2022.01.03 |
| 경사하강법(gradient descent)의 한계 (0) | 2022.01.02 |