

1. motivation
YOLO는 단 1번의 과정으로 모든 prediction을 해서 localization 정확도가 떨어진다
속도가 빠른데 Faster R-CNN보다 성능이 떨어지는 것은 분명 아쉬운 점인데 더 잘할 수 있는 방법이 없을까?
2. 구조
최종적으로 1번만 prediction하는 것이 아니라 각 중간 layer마다 나오는 feature map 크기를 고려하여
적절한 크기의 bounding box를 중간 단계마다 모두 가져오는 방식
이미지의 object scale은 전부 다르다.
그래서 서로 다른 크기의 중간 layer의 feature map에 맞는 적절한 크기의 bounding box를 전부 고려하여
multi scale의 object에 더욱 잘 대응하고자 함
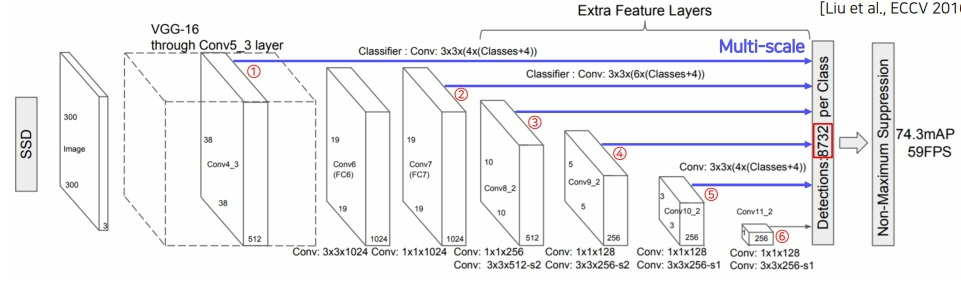
1,2,3,4,5,6 각각에서 feature map 크기를 고려한 적절한 크기의 bounding box로 전부 구해와서 최종단계로 가져옴
8732는 1개의 class당 모든 bounding box의 수
3. 성능
대단히 많은 경우를 고려(R-CNN이 2000개)하는데 구조가 단순해서 YOLO보다 속도도 빠르고 심지어 Faster R-CNN보다 성능도 좋음

물론 각 모델의 input resolution이 전부 다르다는 것을 감안해야함
728x90
'딥러닝 > Computer Vision' 카테고리의 다른 글
| CNN visualization1 - First filter visualization (0) | 2023.06.18 |
|---|---|
| object detection 모델인 RetinaNet과 DETR(DEtection TRansformer) 핵심 아이디어 (0) | 2023.06.17 |
| Deeplab에 사용된 핵심 아이디어 살펴보기 (0) | 2023.05.14 |
| U-Net의 핵심 아이디어 파악하기 (0) | 2023.05.14 |
| 유명한 CNN구조 AlexNet, VGGNet, GoogleNet, ResNet 복습 재활 (0) | 2023.05.12 |