

1. 랭킹에 올라가느냐, 방어하느냐 창과 방패의 싸움
구글이나 네이버의 검색 결과에서 상위를 차지하면 엄청난 트래픽을 가져올 수 있습니다
특히 돈에 관련한 쿼리라면 더더욱 그렇죠
예를 들어 네이버에 '꽃배달'이라는 쿼리를 입력했을때, 1등으로 올라오는 사이트가 있다면, 엄청난 매출을 기대할 수 있겠죠?
그래서 '검색엔진 최적화, SEO, Search Engine Optimization'를 시도하는 업체들은 여러가지 실험을 해보면서 랭킹을 높이기 위해 끊임없이 도전합니다
구글에는 200여가지 랭킹 조건이 있는데 검색엔진 최적화는 이들 조건 사이에서 바늘구멍같은 빈틈을 찾아 랭킹을 올리기 위해 끊임없이 노력하는 거죠
이를 위해 다양한 수단을 동원합니다. 다양한 메타 태그를 부여해보기도 하고, 인기있는 키워드도 분석합니다.
링크를 추가한다던지 사이트맵을 개선하기도 하죠
소스코드까지 다른 형태로 바꿔봅니다.
이렇게 검색엔진이 좋아할 수 있도록 끊임없이 시도하죠. 반면 검색엔진 업체들은 쉽게 랭킹을 올릴 수 없도록 알고리즘을 개선하고 진화시킵니다.
단순히 메타 태그를 몇개 부여한다고 랭킹이 쉽게 올라가서는 곤란하겠죠.
품질이 좋은 문서만 랭킹에 오를 수 있도록 검색엔진 업체들은 계속해서 방어 로직을 개선합니다.
이 싸움은 끝이 없을 겁니다. 아마 검색 서비스가 존재하는 한 계속 되겠죠
어차피 완벽한 알고리즘이란 존재하지 않습니다. 알고리즘은 끊임없이 진화할 것이고, 그럴수록 여러분은 점점 더 똑똑한 검색 엔진을 이용할 수 있게 될거에요
2. 딥러닝, 검색 알고리즘을 더욱 진화시키다
원래 검색엔진의 역할은 쿼리에 정확하게 매칭하는 문서를 찾아주는 것입니다.
구글을 비롯한 요즘의 검색엔진은 충분히 이 역할을 해내고 있죠.
하지만 사람들은 점점 더 똑똑한 검색엔진을 원합니다.
이제는 쿼리의 맥락을 파악하여 적절한 문서를 제시해주는 수준에 이르렀죠.
'소니에서 개발한 회색 콘솔'이란 쿼리를 예로 들어보죠. 이 쿼리에 구글은 정확하게 '플레이스테이션'을 포함한 문서를 정답으로 제시합니다.
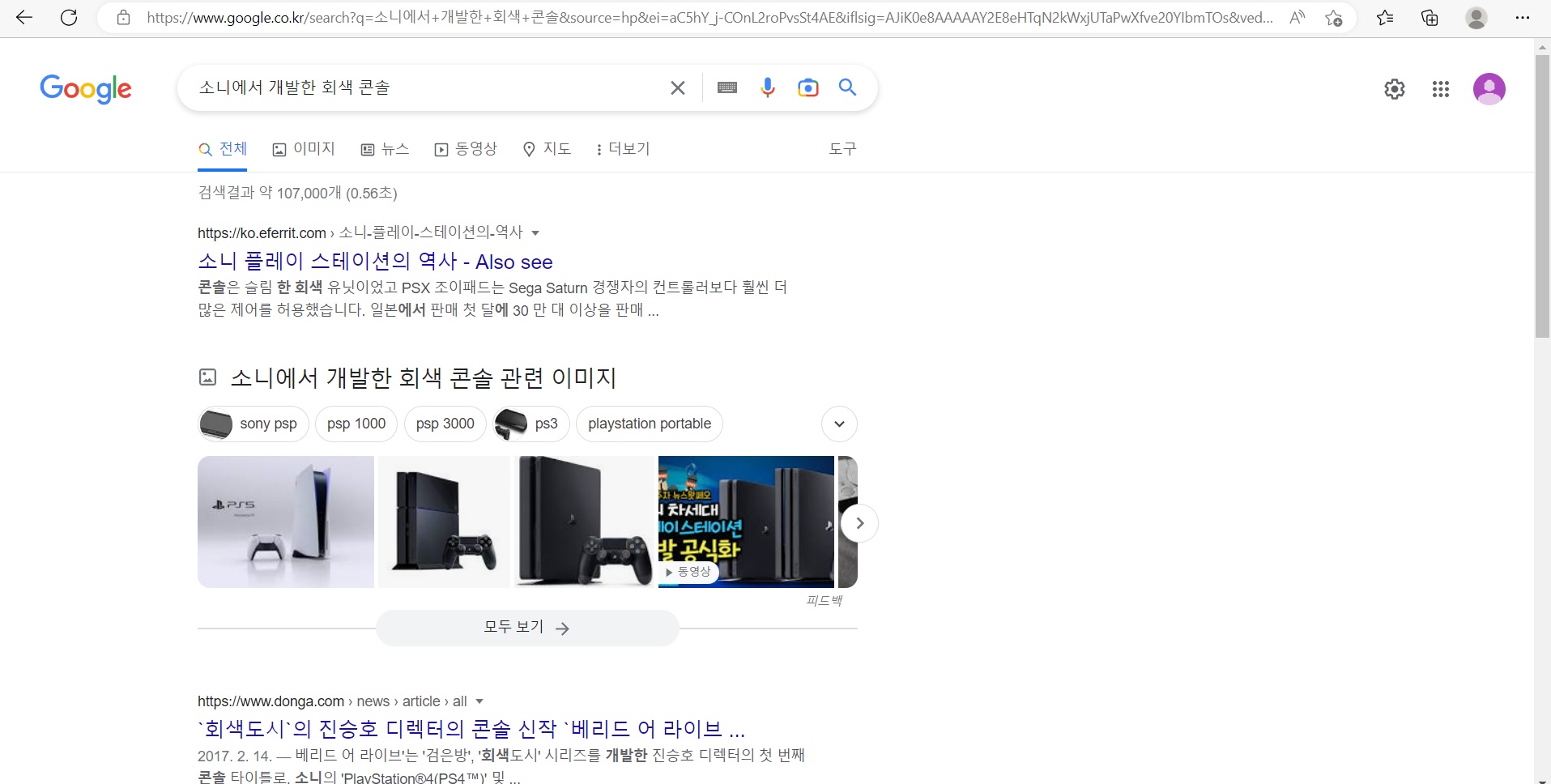
쿼리에는 게임기나 플레이스테이션에 대한 언급이 전혀 없지만 검색엔진은 쿼리를 이해하고, 이에 적합한 문서를 제시하는거죠
이렇게 작동하기 위해서는 검색엔진이 단순히 문서가 해당 단어를 포함하는지 여부만 판단할게 아니라,
단어와 단어 간의 관계를 파악하고 문장의 의미를 정확하게 이해해야합니다.
이때 딥러닝이 문장의 의미를 이해하고 이에 맞는 정답을 찾아주는 역할을 합니다.
예컨대 딥러닝은 유사도 점수를 계산할 때 살펴본 '갤럭시 노트 신제품' 쿼리와 관련해 '삼성 핸드폰 신상'이라는 단어에도 가중치를 줄 수 있습니다.
서로 비슷한 의미를 지니고 있기 때문이죠.
딥러닝은 이처럼 비슷한 의미를 지닌 단어를 비슷한 숫자로 표현할 수 있고 따라서 유사한 의미를 지닌 단어로 판별해낼 수 있습니다.
이에 관련한 구체적인 알고리즘은 7장에서 좀 더 자세히 살펴보겠습니다.
챗봇에서 쓰이는 유사도 판별 알고리즘과 거의 동일한 알고리즘이 검색엔진에도 반영되거든요.
이처럼 자연어 처리에 쓰이는 여러 기술은 검색에서도 매우 유용하게 활용됩니다.
애초에 검색 기술 자체가 인간의 자연어를 보다 정확하게 이해하는 과정이기도 합니다.
딥러닝은 검색 결과뿐만 아니라 검색과 관련한 다양한 분야에도 활용됩니다.
오타 교정이 대표적입니다. 일반적으로 사람들은 매일 입력하는 10개의 쿼리 중 1개 정도는 맞춤법이 틀리기 마련이죠
맞춤법이 틀리면 정상적인 검색 결과를 얻을 수 없겠죠
이 경우 오타를 교정해 바른 쿼리를 입력할 수 있도록 제안하는데, 이때 딥러닝이 오타를 교정할 수 있도록 도움을 줍니다.
예컨대 세바시 발표를 보고 싶어 구글 검색창에 '세바시 15분 프레젠테이션'을 입력해야하는데 실수로 '네바시'라고 입력하고 말았습니다.
이 경우 원래는 의도한 결과가 나오지 않겠죠. 하지만 요즘 구글 검색창은 '세바시'로 교정해서 결과를 보여줍니다.
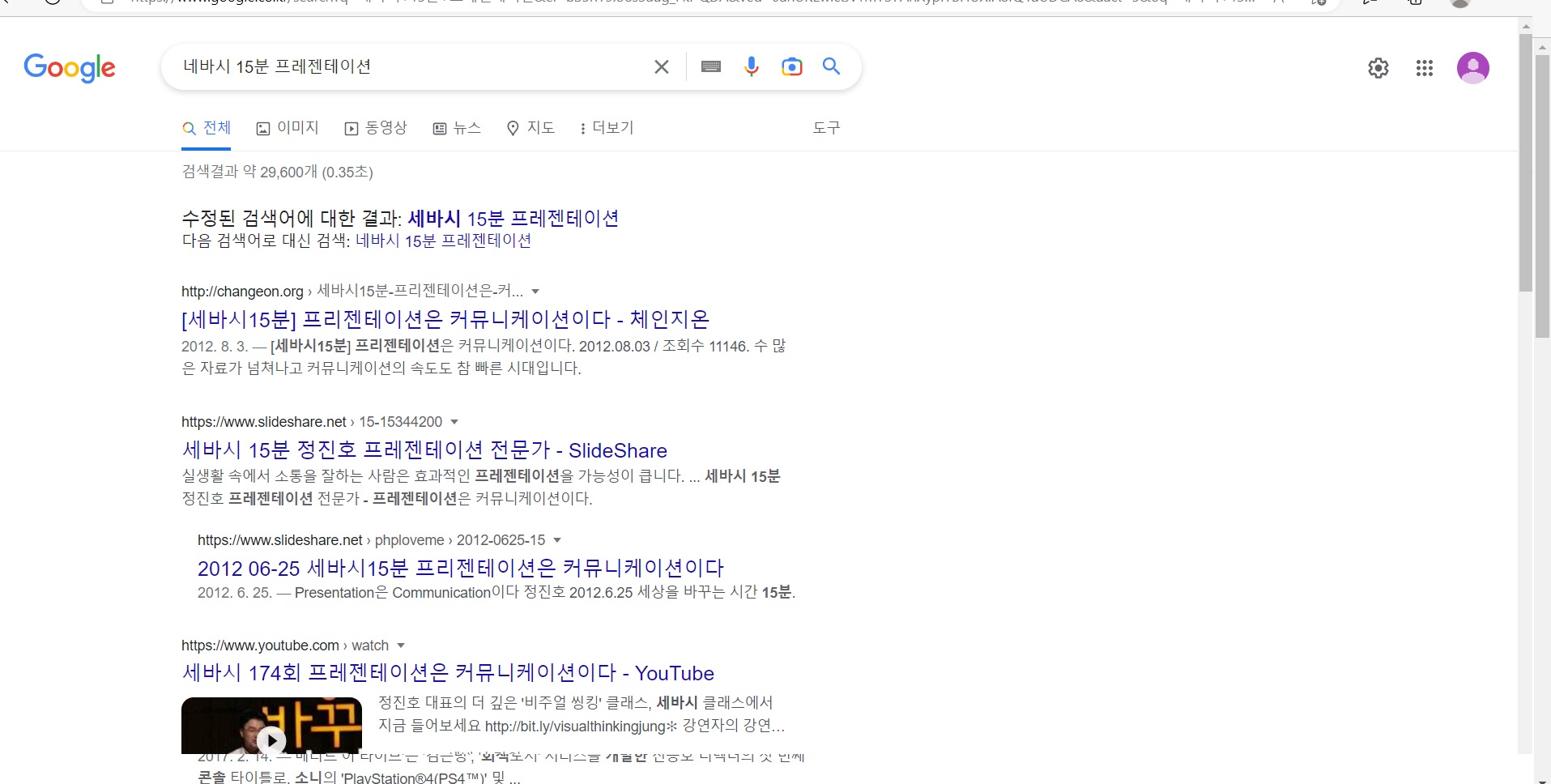
수많은 학습데이터를 통해 어떤 문장이 잘못되었고, 어떤 문장이 정상인지를 판별하고 가장 적합한 문장으로 오타 교정을 제안하는 거죠.
과거에는 편집 거리(edit distance)라고 하여 정상적인 철자보다 얼마만큼 틀렸는지를 계산하여 오타를 교정했지만,
이제는 수많은 데이터로 학습한 딥러닝으로 오타를 훨씬 더 정교하게 교정해냅니다.
뿐만 아니라 최근에는 검색이 단순한 텍스트의 이해를 넘어, 복잡한 문장과 이미지도 이해하고, 번역과 제안까지 하죠.
여기에 마찬가지로 딥러닝이 큰 역할을 하고 있습니다.
3. 구글 MUM, 일상의 언어까지도 이해하다
2021년 상반기에 구글은 MUM(multitask unified model)이라는 기술을 발표합니다.
복잡한 질문에 답하기 위해 딥러닝을 결합한 새로운 기술이죠.
"지난번에 애덤스산에 하이킹 다녀왔는데 올가을에는 후지산을 가보려고 해. 다른 준비가 필요할까?"

MUM은 이렇게 복잡한 쿼리의 의미도 파악하고 결과를 보여줍니다.
먼저, 애덤스산과 후지산을 비교하여 높이나 등산 정보를 찾습니다.
또한 하이킹을 준비하고 있다는 점을 파악하고 하이킹을 위한 적절한 피트니스 운동과 가을 날씨에 맞는 하이킹 장비를 추천하죠.
방대한 사전 정보를 바탕으로 애덤스산과 후지산이 높이는 같지만, 일본 후지산의 가을은 장마기간이므로 방수 재킷이 필요하다는 사실을 알려줍니다.
이때 문서뿐만 아니라 비디오나 이미지 정보도 함께 찾아서 보여주죠.
MUM은 7장 챗봇에서 살펴볼 BERT라는 모델보다 성능이 1000배 더 강력하다고 합니다.
사람이 이해하는 것 이상의 엄청난 성능을 보인다고 할 수 있죠
언어의 장벽을 제거하려는 시도도 하고 있습니다. 아무래도 후지산 하이킹 정보는 주로 일본어로 되어 있겠죠.
구글은 최근 75개 언어를 모두 통합하여 학습하는 모델을 구축했습니다.
그래서 한국어로 '후지산 하이킹'을 검색해도 '후지산에서 가장 전망이 좋은 곳', '유명한 지역 온천', '인기 있는 기념품 가게'등 원래는 일본어로만 볼 수 있었던 웹 문서를 우리말로도 보여줍니다.
이러한 기술로 구글 MUM은 진정한 개인 비서 시대에 성큼 다가섰죠
이하윤의 수필 <메모광>으로 시작해서 많은 이야기를 나눴습니다.
스마트폰은 이제 단순한 분실의 역할을 넘어 똑똑한 검색 서비스를 담고 있습니다.
검색은 점점 더 문서, 비디오, 이미지 같은 형식의 경계, 언어의 경계를 무너트리고 복잡한 질문을 이해하며, 방대한 사전 정보를 바탕으로 추천까지 하는 진정한 개인 비서의 역할을 톡톡히 해내고 있습니다.
앞으로도 검색은 인공지능 시대의 핵심 서비스로 계속 자리매김할 것입니다.
지금처럼 꾸준히 발전한다면 여러분은 어떠한 정보도 빠르고, 정교하게 찾아낼 수 있을겁니다.
'책 읽기 > 비전공자도 이해할 수 있는 AI지식' 카테고리의 다른 글
| 비전공자도 이해할 수 있는 AI지식 26 -시리는 사람의 말을 어떻게 알아듣는가- (0) | 2022.11.09 |
|---|---|
| 비전공자도 이해할 수 있는 AI지식 25 -내 손안에 비서가 있는 시대- (0) | 2022.11.03 |
| 비전공자도 이해할 수 있는 AI지식23 - 사람들이 진짜로 검색 결과를 좋아하는지 아는 방법- (0) | 2022.10.30 |
| 비전공자도 이해할 수 있는 AI지식22 -검색엔진이 우리가 원하는 문서만 보게 만들어주는 비결- (0) | 2022.10.29 |
| 비전공자도 이해할 수 있는 AI지식21 -세상을 놀라게 한 페이지랭크 알고리즘- (0) | 2022.10.22 |