

1. 사람들은 최신 지식을 원한다
기술은 항상 발전하고 과거의 지식은 새로운 지식으로 끊임없이 업데이트됩니다
대개는 새로운 정보가 옛날 정보보다 더 좋죠. 최신 문서에 좀 더 높은 점수를 주는 건 어찌 보면 당연합니다
특히 뉴스 같은 경우에는 최신 문서의 강점이 극대화됩니다. 누구도 오래된 뉴스를 보고 싶진 않을테니깐요
'갤럭시 노트 신제품'같은 쿼리가 좋은 예입니다. 여러분이 검색엔진에서 찾고 싶은 문서는 갤럭시 노트의 최신 기종 소식일 것입니다.
4~5년 전에 출시한 구버전 갤럭시 노트 소식이 상위에 올라오는걸 원치는 않겠죠
그래서 일반적으로 최신 문서일수록 점수 경쟁이 치열합니다. 반면 오래된 문서들은 비교적 점수 차이가 적죠.
1주일 이내에 발행된 문서끼리는 하루 차이로도 점수 차이가 많이 나지만 2년 전에 발행된 문서는 3년 전 문서와 별 차이가 없습니다.
그 정도 시간이 지나면 이미 정보의 의미가 많이 약해진다고 보기 때문이죠

여기서 중요한건 최신 문서일수록 항상 점수가 높다는 점입니다.
그렇다면 오래된 문서들은 더 이상 검색 결과 상단을 차지할 수 없게 될까요? 꼭 그렇지만은 않습니다.
최신에 관한 점수가 떨어져도 점수를 유지해줄 또 다른 조건을 알아보죠
2. 품질 좋은 문서란 무엇인가
품질이 좋은 문서란 어떤 문서일까요?
여기에는 정말 다양한 기준이 있습니다.
앞서 구글의 랭킹 조건을 얘기하면서 잠깐 언급했던 '문서가 길수록', '문서 로딩이 빠를수록', '모바일에서 잘 보일수록' 같은 조건이 모두 품질 범주에 포함됩니다.
품질이 좋은 문서란, 검색 쿼리에 관계없이 항상 좋은 문서를 말합니다.
예를 들어 문서가 길면 짧은 문서보다 더 품질이 좋은 문서라 할 수 있죠
한두 문장으로 끝나는 글보다는 긴 글이 좀 더 유용한 내용을 담고 있을 확률이 크겠죠.
또는 권위 있는 사이트에 실려 있다면 품질이 좋은 문서로 볼 수 있습니다. 아무래도 개인 블로그의 글보다는 <뉴욕 타임스>에 올라온 뉴스 기사가 훨씬 더 권위가 있겠죠
위키백과의 글도 마찬가지 입니다. 위키백과는 집단지성의 결정체로 훌륭한 정보의 출처로 권위를 인정받기 때문에 위키백과의 문서도 대부분 좋은 문서로 분류되죠
이처럼 권위있는 사이트의 문서는 좋은 품질의 문서로 볼 수 있습니다.
그렇다면 사이트나 문서의 권위는 어떻게 측정할 수 있을까요?
과거에는 좋은 사이트를 제대로 구분해내지 못했고, 당연히 검색 랭킹도 제대로 작동하지 않았습니다.
엉뚱한 문서가 상위에 등장하는 경우가 잦았고 심지어 스팸사이트가 검색 결과 상위를 온통 차지하기도 했었죠.
사용자들은 검색 결과에 불만을 품기 시작했습니다.
수학계에 에르되시 수라는게 있습니다.
전세계를 돌아다니며 평생 수학연구에만 몰두해온 에르되시 팔은 평생 1500여편의 논문을 쓴 것으로 유명한데, 논문 대부분을 다른 학자들과 공동 집필했습니다.
혼자서 연구하기보다는 전 세계를 돌아다니며 훌륭한 연구자와 함께 연구하는 것을 평생의 가치로 여긴 분이었죠.
그러다 보니 수학자들 사이에서는 에르되시와 함께 공동 논문을 쓴 경험을 엄청난 영예로 여깁니다.
에르되시 수는, 에르되시와 몇 단계에 걸쳐 네트워크로 연결되어 논문을 저술했는지 나타내는 수입니다.
에르되시 본인은 0번이고 그와 직접 공동 논문을 쓴 학자는 모두 512명이고 이들은 에르되시 수 1번이 부여되죠.
그리고 이 512명과 공동 논문을 쓴 사람은 에르되시 수 2번입니다. 이런 식으로 n번은 n-1번과 공동 논문을 저술한 사람이 부여받는 번호입니다.
아무런 접점이 없는 사람은 무한대가 부여됩니다.
수학 저널에 논문을 한편이라도 기고한 수학자의 경우, 거의 대부분이 에르되시 수 8 이하에 해당한다고 알려져있습니다.
당연히 숫자가 낮을수록 영예가 높아집니다. 뛰어난 업적을 남긴 수학자일수록 에르되시 수가 낮은 경향이 있죠
그래서 에르되시 수는 농담처럼 얼마나 더 뛰어난 수학자인지를 나타내는 척도로 쓰이기도 합니다.
(심지어 돈받고 팔았던 경우도 있었다고 함)
(참고로 최근 필즈상 수상자 허준이 교수도 3번이고.. 일론 머스크는 4번, 구글의 창업주 세르게이 브린과 래리 페이지도 3번)
논문을 평가하는 가장 중요한 척도는 인용 횟수입니다. 다른 논문에 많이 인용될수록 좋은 논문이라는 점은 논문을 한 편이라도 써보신 분들은 이미 잘 알고 있을 겁니다.
에르되시 수가 낮을수록 실력이 뛰어나다고 본다면, 인용 횟수가 많다는 것은 뛰어남을 증명하는 척도로 볼 수 있습니다.
이 2가지를 잘 조합한다면 문서의 품질을 정교하게 측정할 수 있지 않을까요?
실제로 논문의 인용횟수를 활용해 문서의 품질을 평가하는, 세상을 놀라게 한 역사적인 알고리즘이 탄생했습니다
3. 페이지 랭크 알고리즘, 세상을 바꾸다
1998년 스탠퍼드에서 박사과정 중이던 브린과 페이지는 문서의 품질을 평가하는 획기적인 알고리즘을 고안합니다.
"유명한 사이트가 많이 가리킬수록 문서의 점수가 올라가는 알고리즘으로, 좋은 논문은 인용횟수가 많다"는 아이디어에서 출발했죠
여기에 에르되시 수가 낮을수록 권위가 높아진 것처럼 권위 있는 사이트에 가중치를 높였습니다.
예를 들어 개인 블로그가 내 문서를 링크하는 것보다 <뉴욕 타임스>가 내 문서를 소개한다면 내 문서의 점수가 훨씬 더 많이 올라가는 거죠
이 알고리즘의 이름은 페이지 랭크(page rank)입니다. 웹 문서를 랭크했다는 의미이기도 하지만, 구글 창업자 중 한명인 래리 페이지의 이름에서 따왔기 때문이기도 합니다.
2가지 의미를 모두 지닌 재미있는 이름이죠. 그렇다면 간단하게 페이지 랭크 점수를 계산해보죠

몇 개의 링크가 문서를 인용하고 있는지(횟수)와 현재 웹 문서의 점수(권위)를 먼저 살펴야 합니다.
모든 웹 문서의 점수 합은 100%입니다.
각각의 웹 문서는 100%에서 점수를 할당받아 나눠 갖죠. 여기서 웹 문서 E의 점수는 8%입니다.
그렇다면 어떻게 해서 웹 문서 E가 8%의 점수를 얻었는지 계산해봅시다.
웹 문서 E를 가리키는 문서는 총 6개입니다. 이 중 점수가 2%인 문서가 G,H,I,J,K로 5개이고 F는 4%의 점수를 갖습니다.
페이지 랭크는 내 웹 문서의 점수를 링크한 다른 웹 문서에게 나눠주는 방식입니다.
점수가 2%인 문서는 다른 문서에게 최대 2%만 줄 수 있지만, 점수가 4%인 문서 F는 다른 문서에 최대 4%를 나눠줄 수 있죠
따라서 F가 링크한 문서는 높은 점수를 받을 확률이 커집니다.
이렇게 권위의 차이가 생기고 이는 에르되시 수가 낮을수록 명성을 얻는 것과 유사합니다
자신을 향하는 화살표의 수는, 즉 링크된 횟수는 많을수록 좋습니다.
웹 문서 E를 보면 총 6개의 문서가 문서 E를 링크하고 있고, 그래서 총 6개 문서의 점수를 합산하여 점수를 얻습니다.
그런데 각각의 문서가 자신의 점수를 모두 나눠주는건 아닙니다. 해당 웹 문서가 링크한 문서의 개수만큼 점수를 쪼개서 나눠줍니다.
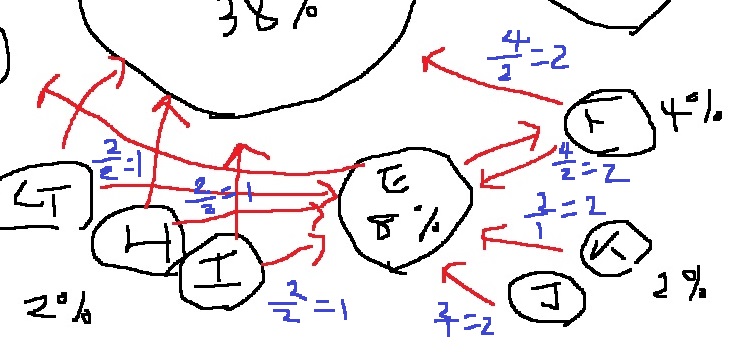
예를 들어 웹 문서 F의 점수는 4%이며, 문서 2개를 링크하고 있습니다.
따라서 자신의 점수를 링크 개수로 쪼갠 4%/2 = 2% 점수를 링크한 문서에 각각 나눠줍니다.
반면 웹 문서 K는 자신이 링크한 문서가 문서 E 하나밖에 없으므로 자신의 점수 2%를 모두 문서 E에 나눠줍니다.
결국 웹 문서 E가 F와 K에게서 받는 점수는 동일합니다. 이같은 원리로 웹 문서 E의 점수를 모두 계산해보면 다음과 같습니다.
G,H,I,J,K,F 순서로..
1 + 1 + 1 + 2 + 2 + 2 = 9%
E의 총점은 9점으로, 9%입니다. 그런데 웹 문서 E는 8%로 표기되어 있는데 이는 댐핑 팩터(Damping Factor)때문입니다.
댐핑 팩터란 쉽게 말해 사용자들이 싫증을 낼 확률을 반영한 값입니다.
즉 링크를 따라가 웹 문서를 읽다가 어느 순간 흥미를 잃어 해당 문서에서 벗어날 확률이 15%라면, 댐핑 팩터는 이 값을 반영하여 0.85가 됩니다.
페이지 랭크 논문에서도 댐핑 팩터의 기본값을 0.85로 정했습니다.
이 때문에 문서 점수는 9점이지만, 댐핑 팩터를 반영해 소수점 이하는 적절히 올림하면..
$$9\times 0.85\approx 8$$
이렇게 댐핑 팩터를 반영한 최종 점수는 8%입니다.
사용자들이 얼마나 싫증을 잘 내는지, 즉 댐핑 팩터의 비율이 얼마인지에 따라 해당 문서의 점수와 전체 순위는 많이 달라질 수 있습니다.
이제 권위가 어떻게 점수에 차이를 내는지 살펴보겠습니다.
이번에는 동일하게 링크를 하나씩만 받은 웹 문서 A와 C를 살펴보고자 합니다.

웹 문서 A와 C는 동일하게 하나의 링크만 받았지만 점수는 각각 3%, 33%로 차이가 많이 납니다.
그 이유는 A와 C를 링크한 웹 문서 D와 B의 점수 차이가 크기 때문입니다.
D는 자체 점수가 4%밖에 되지 않는, 아마 개인 블로그 정도로 보입니다.
그래서 댐핑 팩터 0.85를 반영하면 웹 문서 A는 3%정도의 점수밖에 얻지 못합니다.
반면 웹 문서 B는 뉴욕타임스같은 매우 권위 있는 사이트로 보입니다.
점수가 38%나 되기 때문에 웹 문서 B에 링크가 걸린 웹 문서 C는 댐핑 팩터를 반영해도 점수가 33%나 됩니다.
$$38\times 0.85\approx 33$$
이처럼 권위 있는 문서가 참조하면 점수가 더욱 높아집니다.
링크된 수가 같아도 어떤 문서에 링크되었는지에 따라 점수 차이가 크게 벌어지죠.
특히 웹 문서 E는 링크가 많음에도 불구하고 링크를 하나밖에 받지 못한 웹 문서 C보다도 점수가 한참 낮습니다.
그만큼 페이지 랭크에서는 권위 있는 문서에서 링크를 받는 것이 중요합니다.
이것이 바로 페이지 랭크의 작동 원리입니다.
그리고 이 원리에 따라 페이지 랭크는 마법처럼 작동했습니다.
권위 있는 사이트가 많이 참조할수록 순위가 올라가는 구조 덕분에 권위가 없는, 이른바 스팸 사이트는 아무리 링크를 늘려봐야 순위에 오를 수 없게 되었습니다.
점차 검색엔진에서 스팸이 사라지기 시작했고, 높은 검색 품질을 무기로 구글은 검색 시장을 하나 둘 점령하기 시작했습니다.
2020년 기준으로 구글의 전 세계 검색 시장 점유율은 92%가 넘습니다. 이를 시작으로 구글은 안드로이드, 크롬, 유튜브 등으로 시장을 확대해나갔고,
이제 구글은 2022년 상반기 기준 전 세계에서 시가총액이 4번째로 높은 2300조원의 가치를 지닌 세계 최고의 기업으로 성장했습니다.
이 모든 것의 시작은 페이지 랭크였습니다.

'책 읽기 > 비전공자도 이해할 수 있는 AI지식' 카테고리의 다른 글
| 비전공자도 이해할 수 있는 AI지식23 - 사람들이 진짜로 검색 결과를 좋아하는지 아는 방법- (0) | 2022.10.30 |
|---|---|
| 비전공자도 이해할 수 있는 AI지식22 -검색엔진이 우리가 원하는 문서만 보게 만들어주는 비결- (0) | 2022.10.29 |
| 비전공자도 이해할 수 있는 AI지식20 -사람들은 어떻게 원하는 검색 결과만을 볼 수 있는가- (0) | 2022.10.22 |
| 비전공자도 이해할 수 있는 AI지식19 -구글이 셀 수없이 많은 문서를 모두 수집한 비결- (0) | 2022.10.21 |
| 비전공자도 이해할 수 있는 AI지식 18 -인터넷 세상을 지배한 구글의 등장- (0) | 2022.10.19 |