


1. Naive bayes classifier
bag of words로 얻은 sentence나 document를 특정 category로 분류하는 모델링중 가장 간단한 것이 naive bayes classifier
d개의 문서(input)가 c개의 class에 분류될 수 있다면 특정한 문서 d는 어떤 클래스로 분류하는 것이 합리적인가?
d가 주어질 때 모든 c에 대해 C=c의 조건부확률이 가장 높은 c에 분류하는 것이 합리적이다.

사후확률을 가장 높이는 maximum a posteriori
베이즈 정리를 이용하면 위 식은 아래와 같아진다.
그런데 주목할 점은 우리는 특정한 문서 d에 주목한다는 것이다.
특정한 문서 d가 뽑힐 확률 P(d)는 하나의 상수일 것이다.
상수 값은 최대화하는데 의미가 없으므로 P(d|c)P(c)/P(d)를 최대화하는 것과 P(d|c)P(c)를 최대화하는 것은 동일하다.
그러므로 식은 아래와 같이 쓸 수 있다.
P(d|c)는 무엇인가? 특정한 class가 C=c로 고정되었을 때 주어진 문서 d가 그러한 class에 속할 확률이다.
bag of words에서 문서(document)나 문장(sequence)은 단어들의 곱사건으로 나타난다는 것을 알 수 있었다.
단어 one hot vector w1,w2,w3,...,wn이 하나의 공간에 동시에 일어난 것이 d와 같으므로
P(d|c) = P(w1,w2,w3,...,wn|c)
그런데 class가 C=c로 주어질 때 w1,w2,...wn들이 조건부독립(conditional independence)라고 한다면?
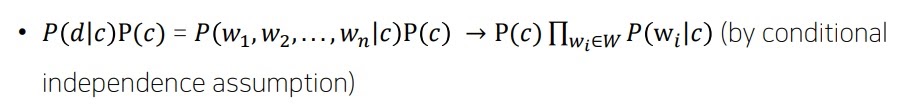
왜 그럴까?
조건부독립의 정의는 분명히 X,Y가 Z가 주어질 때 조건부독립이라면 P(X|Y,Z)=P(X|Z)로 조건부에서 없어지는 것인데?

---------------------------------------------------------------------------------------------------------------------
(증명)
https://deepdata.tistory.com/175
조건부독립의 성질
만약 w1,w2,...wn이 c가 주어질 때 서로 조건부독립이라면 P(w1,w2,....,wn|c)=n∏i=1P(wi|c)이다? n=2라고 한다면 P(w1|w2,c)=P(w1|c)이므..
deepdata.tistory.com
---------------------------------------------------------------------------------------------------------------------
실제로 naive bayes는 이러한 조건부 독립가정을 하고 있다.

이제 문서 d의 class에 속할 확률을 추정하는 것은
class의 사전확률 P(c)와 개별 단어가 특정 class내에서 존재할 확률 P(wi|c)를 알면 구할 수 있다.
2. 예제로 계산해보는 분류확률

cv라는 class는 4개중 2개 있고 nlp라는 class는 4개중 2개 있으므로 각각 class의 사전확률은
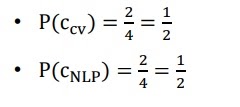
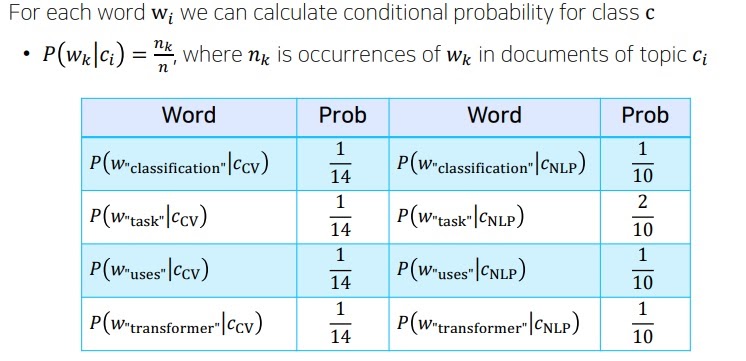
각 class 내에서 test에 존재하는 단어 classification, task, uses, transformer가 등장할 확률을 구해본다면
예를 들어 classification이라는 단어가 cv라는 class 내에 존재할 조건부확률은
cv라는 class에는 14개의 단어가 존재하고 classification은 1개만 존재하므로 1/14
단어 수를 셀때 중복을 빼야하는거 아니냐고?
one hot encoding할 때야 뺀거지 지금은 존재하는 하나의 데이터인데 뺄 이유가 없다.
실제로 sentence의 one hot vector를 계산할 때 위에서 첫번째 문장의 경우 really 가 두번 더해진거 확인 가능하다.
중요한 점은 test의 class를 예측하고 싶기때문에 당연한거지만 test내 존재하는 단어들의 class 조건부확률만 구하면 된다
최종적으로 test의 sentence가 각 class cv,nlp에 속할 조건부확률은

cv에 속할 확률이 높으므로 cv로 분류하는 것이 합리적이다.
'딥러닝 > NLP' 카테고리의 다른 글
| Word2Vec의 핵심 아이디어 (0) | 2022.02.05 |
|---|---|
| naive bayes classifier의 문제점을 보완하는 Laplace smoothing (0) | 2022.02.04 |
| transformer은 NLP의 트렌드를 어떻게 바꾸었을까 (0) | 2022.01.28 |
| bag of word - 왜 단어는 숫자 벡터로 표현해야할까? - (0) | 2022.01.25 |
| 텍스트마이닝(Text Mining)과 정보검색(information retrieval)이란? (0) | 2022.01.25 |