

1. 세그먼트 트리의 표현
배열의 크기 N이 2의 거듭제곱꼴이면 Perfect binary tree이므로 트리의 높이 h는 각 높이의 노드의 수가 x개이면
$$h=log_{2} x$$

full binary tree라면 어떨까?
어떤식으로 구성되어 있느냐에 따라 조금 달라진다.....
$h= \left \lceil log_{2} x \right \rceil $이기도 하고.. $H= \left \lceil log_{2} x \right \rceil +1 $ 이기도 하고...

따라서 세그먼트 트리를 표현할 때, 배열을 이용해서 표현할 수 있고 세그먼트 트리 배열의 크기는 항상 그 크기가 일정한 높이 h인 perfect binary tree의 노드 수로 나타낼 수 있다
비어있는 부분은 0으로 채우든지 하면 되니까..
----------------------------------------------------------------------------------------------------------------------
그러면 공간을 낭비하는 것이 아니냐? 생각보다 공간을 낭비하지는 않는다
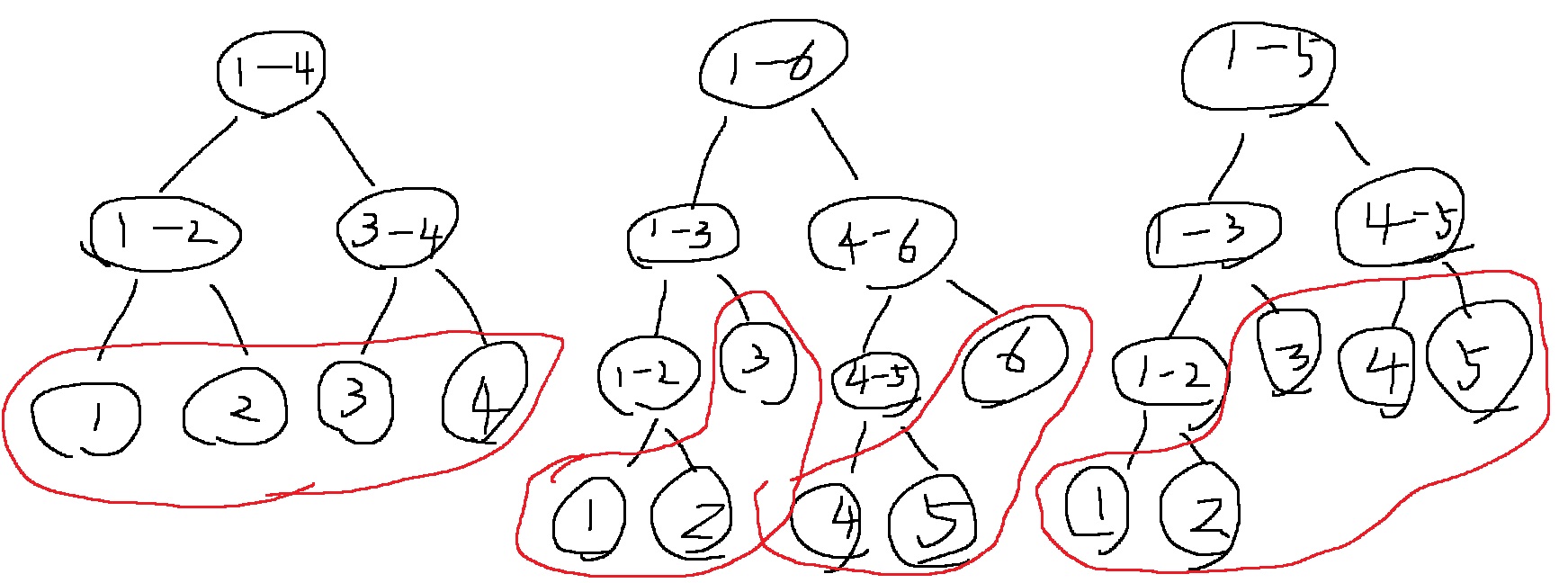
세그먼트 트리는 특징이
깊이가 가장 깊은 리프노드의 깊이와, 가장 깊지 않은 리프노드의 깊이는 차이가 1보다 작거나 같다.
조금만 생각해보면 당연한데,
최상단의 구간길이가 2의 배수이면?
1,2,3,4,5,6
1,2,3 4,5,6
1,2 3 4,5 6
1 2 4 5
혹은 perfect binary tree를 원한다면..?
1,2,3,4
1,2 3,4
1 2 3 4
반면 최상단 구간 길이가 2의 배수가 아니라면?
1,2,3,4,5
1,2,3 4,5
1,2 3 4 5
1 2
이렇게 가장 깊은 리프노드의 깊이와 가장 깊지 않은 리프노드의 깊이차이는 반드시 1아니면 0이 된다
------------------------------------------------------------------------------------------------------------------
높이 h의 리프노드 수가 x이면, $x = 2^{h}$이고 h=0부터 h까지 전부 더하면 노드의 수가 된다.
이는 초항이 1이고 공비가 2이며 항의 수가 h+1개인 등비수열의 합과 같으므로 $n=2^{h+1} - 1$
그러면 문제는, 주어진 배열 A의 크기가 N인 세그먼트 트리의 높이 h를 알아야 세그먼트 트리를 표현하기 위한 노드 수 n을 구하는데...
높이를 어떻게 구하지??
full binary tree는 높이가 제각각이라며...
하지만 세그먼트 트리는 가장 깊은 리프노드와 가장 깊지 않은 리프노드의 깊이 차이가 1보다 작거나 같으므로...

항상 위와 같은 경우만 가능함
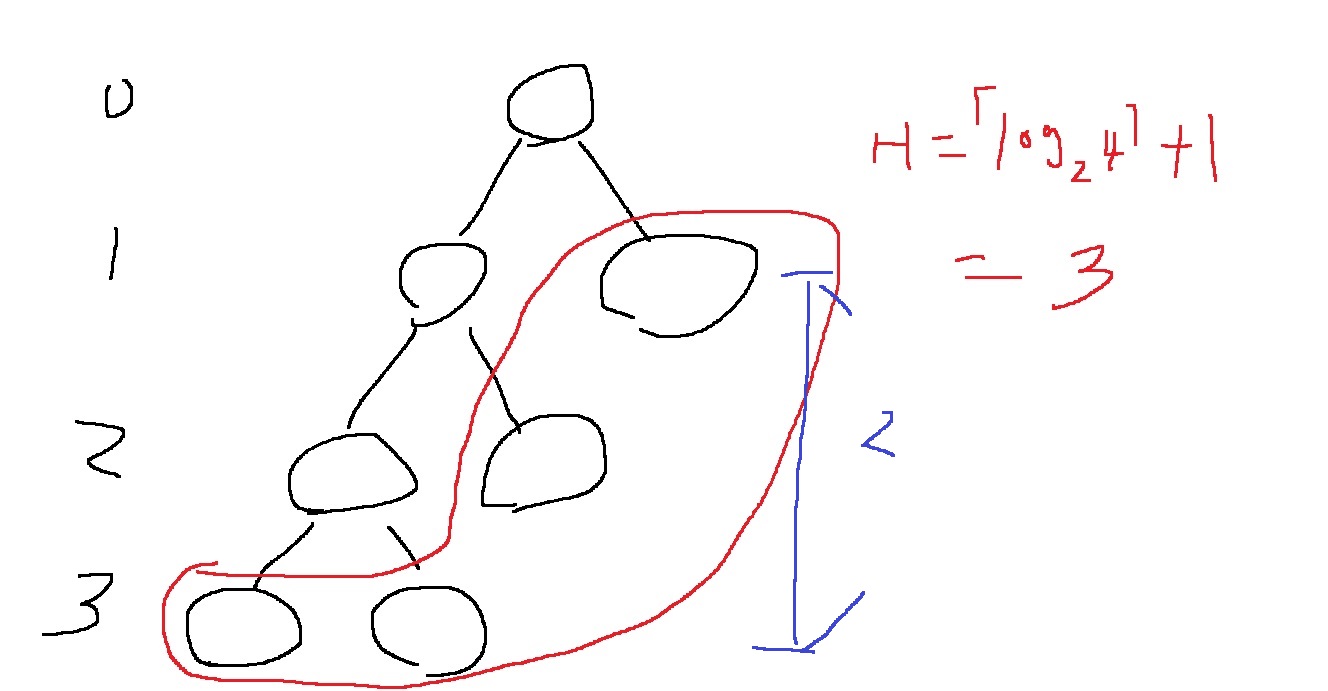
위의 경우는 깊이 차이가 2이므로, 세그먼트 트리로 불가능하다
따라서 배열의 크기가 N인 세그먼트 트리의 리프 노드 수는 N개이므로,
세그먼트 트리의 높이 $h= \left \lceil log_{2} N \right \rceil $로 구할 수 있다.
1-1) 따라서 세그먼트 트리를 표현하기 위한 배열의 크기는... 주어진 수열의 크기가 N일때,
$$2^{\left \lceil log_{2} N \right \rceil + 1} - 1 $$
1-2) 각 노드의 번호는 완전이진트리에서 번호를 표현하는 것처럼...
루트 노드는 1번이고 왼쪽부터 2,3,4,5,...
빈 부분도 물론 번호를 세준다
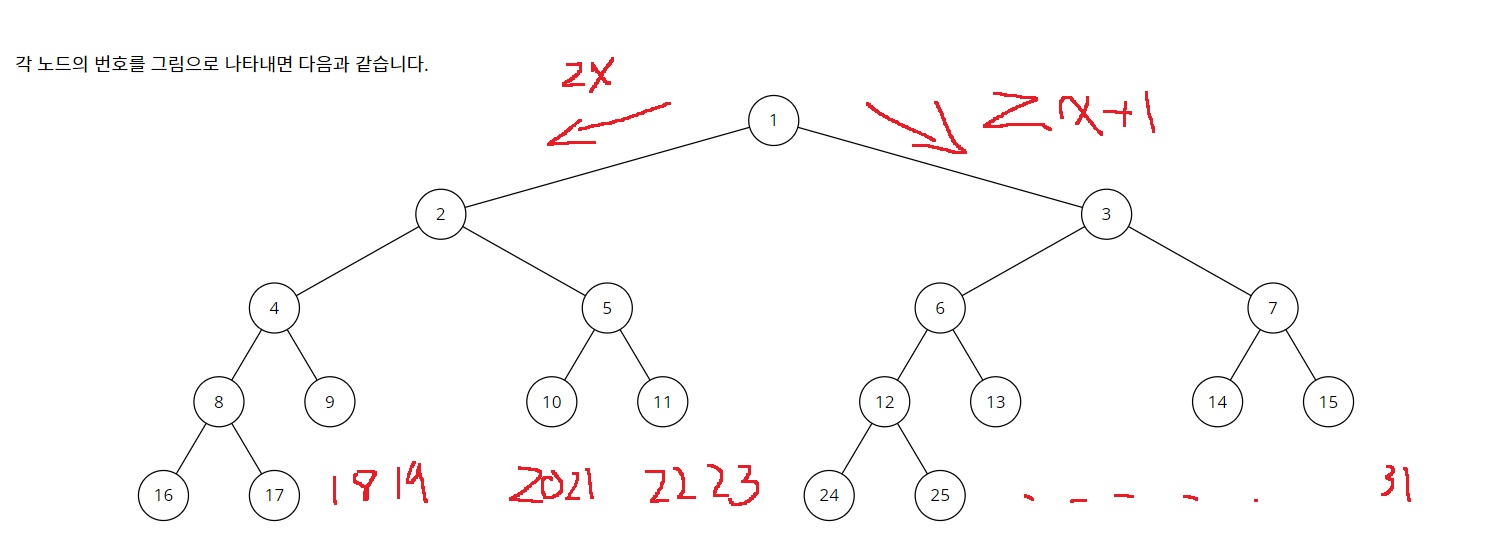
루트 노드를 1번이라고 하면, 좋은 점은 부모 노드가 X번이면 왼쪽 자식은 2X번이고 오른쪽 자식은 2X+1로 간단하게 접근할 수 있다는 특징이 있다
2. 구현 예시 - 구간의 합을 저장하는 세그먼트 트리 생성하기
구간의 범위가 [A_start,A_end]일때, A_start와 A_end가 같다면, 리프노드를 나타내고
리프노드는 배열 A에서 A_start(=A_end)번에 해당하는 수를 저장해야한다.
리프노드가 아니라면, 왼쪽 자식과 오른쪽 자식을 각각 구해서 이들의 합을 저장해야한다.
구간의 절반은 (A_start+A_end)//2로 구할 수 있어서 왼쪽 구간은 [A_start,A_mid]
오른쪽 구간은 [A_mid+1, A_end]로 나타낼 수 있다
부모의 노드 인덱스가 tree_index라면 왼쪽 자식의 노드 인덱스는 2*tree_index이고 오른쪽 자식은 2*tree_index+1이다.
이를 이용해서 재귀호출을 해서 왼쪽 자식과 오른쪽 자식에 저장된 값을 구하고 현재 노드에 저장된 값을 두 자식의 합으로 저장한다
def create_segment(A,tree,A_start,A_end,tree_index):
#리프노드라면, 배열의 해당 수를 트리 노드에 저장해야함
if A_start == A_end:
tree[tree_index] = A[A_start]
return tree[tree_index]
#리프노드가 아닌경우
else:
#왼쪽과 오른쪽을 구분하기 위해
A_mid = (A_start+A_end)//2
#부모 인덱스가 tree_index이고 [A_start,A_end]를 저장한다면
#왼쪽 구간은 [A_start,A_mid]
#왼쪽 자식의 노드 인덱스는 2*tree_index
left_node = create_segment(A,tree,A_start,A_mid,2*tree_index)
#오른쪽 구간은 [A_mid+1,A_end]
#오른쪽 자식의 노드 인덱스는 2*tree_index+1
right_node = create_segment(A,tree,A_mid+1,A_end,2*tree_index+1)
#부모 인덱스에 저장된 값은, 왼쪽 자식과 오른쪽 자식의 합이다.
tree[tree_index] = left_node + right_node
return tree[tree_index]
return은 안해도 되긴한데 너무 재귀함수에 return을 안쓰는것 같아서 일부러 return을 써봤음
안쓰고 싶다면 이렇게 만들 수 있겠지?
def create_segment(A,tree,A_start,A_end,tree_index):
#리프노드라면, 배열의 해당 수를 트리 노드에 저장해야함
if A_start == A_end:
tree[tree_index] = A[A_start]
#리프노드가 아닌경우
else:
#왼쪽과 오른쪽을 구분하기 위해
A_mid = (A_start+A_end)//2
#부모 인덱스가 tree_index이고 [A_start,A_end]를 저장한다면
#왼쪽 구간은 [A_start,A_mid]
#왼쪽 자식의 노드 인덱스는 2*tree_index
create_segment(A,tree,A_start,A_mid,2*tree_index)
#오른쪽 구간은 [A_mid+1,A_end]
#오른쪽 자식의 노드 인덱스는 2*tree_index+1
create_segment(A,tree,A_mid+1,A_end,2*tree_index+1)
#부모 인덱스에 저장된 값은, 왼쪽 자식과 오른쪽 자식의 합이다.
tree[tree_index] = tree[2*tree_index] + tree[2*tree_index+1]
이대로 넘어가기는 아쉬우니까 진짜 맞는지 실험은 해봐야겠지
세그먼트 트리의 노드 수는 $$2^{\left \lceil log_{2} N \right \rceil + 1} - 1 $$으로 구한다고 했지만
전체 트리 배열은 인덱스를 1~n까지 세기 위해 [0]*(n+1)로 초기화해야한다
import math
A = [1,2,3,4,5,6,7,8,9,10]
#배열의 크기 N
N = len(A)
#세그먼트 트리의 노드 수
n = 2**(math.ceil(math.log2(N))+1)-1
#세그먼트 트리의 크기
#[0]*n으로 하면... 0~n-1까지만 가능이라
#[0]*(n+1)로 해서 노드 인덱스가 1~n까지 가능하게
tree = [0]*(n+1)
#전체 구간은 [0,N-1]
#루트 노드의 인덱스는 1번
create_segment(A,tree,0,N-1,1)
print(tree)
[0, 55, 15, 40, 6, 9, 21, 19, 3, 3, 4, 5, 13, 8, 9, 10, 1, 2, 0, 0, 0, 0, 0, 0, 6, 7, 0, 0, 0, 0, 0, 0]
일단 숫자 채우면 이런식으로 나와야함

번호 인덱스가 맞는지 보면 되겠지?

해보면 맞게 한듯?
3. 세그먼트 트리로 임의의 구간의 합을 구하는 방법
세그먼트 트리를 만들었으면 이제 임의의 구간의 합을 물어볼때 구간의 합을 구할 수 있어야 비로소 쓸모가 있겠지
구간 [left,right]가 주어질때, 트리를 루트부터 순회하면서 각 노드에 저장된 구간의 정보와 left,right의 관계를 살펴봐야한다
특정 노드에 저장된 값의 구간이 [start,end]라고 한다면, 트리를 순회하다가 [left,right]와 [start,end]의 관계는 어떤 경우가 있을까

3-1) 첫번째로 두 구간이 서로 겹치지 않는 경우이다
left > end or right < start로 나타낼 수 있다.
left > end이면 [start,end] 다음에 [left,right]가 존재하는 것이고, right < start이면, [start,end]앞에 [left,right]가 존재하는 것이다.
이런 경우에는 더 이상 탐색을 할 필요가 없어서 0을 return
왜 더 할 필요가 없을까?
루트부터 탐색을 해서 내려가는데, 서브트리의 루트가 [start,end]라면, 그 아래 자식들은 모두 [start,end]에 포함되는 구간들이다.
따라서 [left,right]와 완전히 겹치지 않는다면, 그 아래도 당연히 겹치지 않는다

빨간색 A부분의 루트가 [0,4]를 나타내고 있는데, 그 아래는 [0,4]의 부분 구간들이다.
따라서 [5,8]의 합을 구하고 싶은데, [0,4]를 만난다면 그 아래는 탐색할 필요도 없다
3-2) 두번째로는 [left,right]가 [start,end]를 완전히 포함하는 경우이다.
left <= start and end <= right인 경우인데,
이 경우는 해당 노드의 값 tree[tree_index]를 가져오고 더 이상 탐색할 필요가 없다
왜냐하면 위의 이유와 똑같게 해당 노드의 아래는 [start,end]의 부분구간으로,
이미 해당 노드의 값이 아래 자식들의 값을 모두 더한 값을 가지고 있어서 탐색하는 것이 비효율적이다

[5,9]의 합을 구하고 싶다고? 그러면 5-9 노드에 저장된 값만 구해오면.. 그 아래는 볼 필요도 없다
3-3) 세번째로는 [start,end]가 [left,right]를 포함하고 있는 경우이다.
이런 경우에는 왼쪽과 오른쪽 자식으로 나누어서 탐색을 수행해야한다.
왜냐? 왼쪽과 오른쪽 두 부분에 내가 원하는 값이 있을 수 있기 때문에
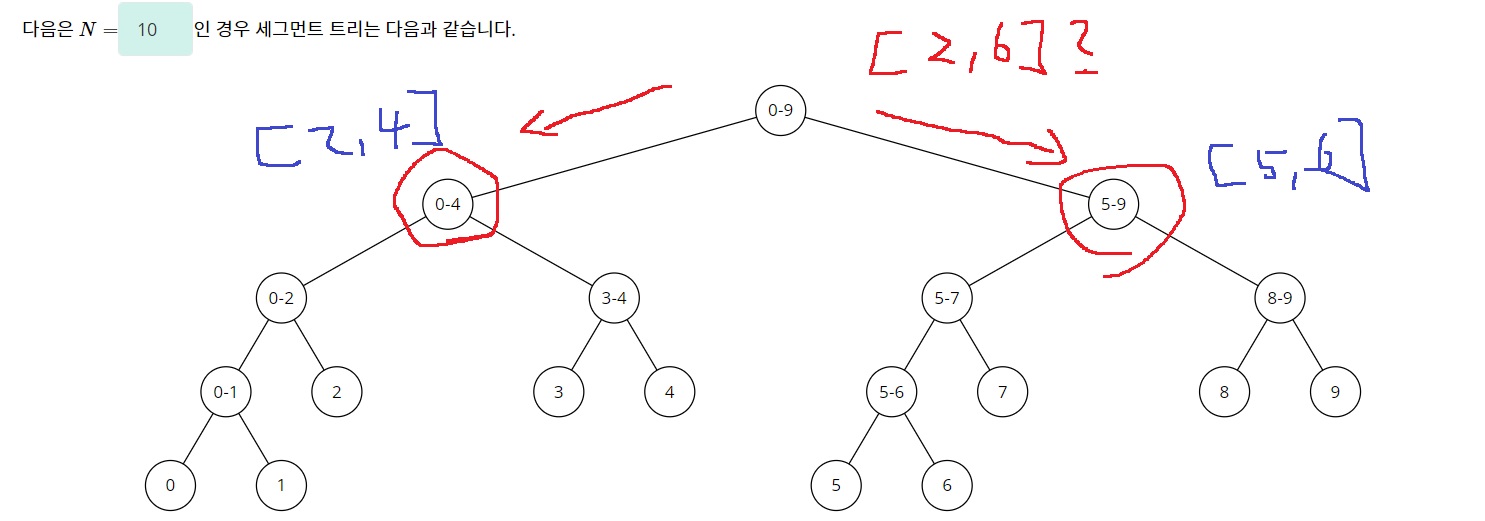
[2,6]에 속하는 값들의 합을 구하고 싶은데 처음 루트 노드의 [0,9]는 [2,6]을 모두 포함하고 있다
그래서 왼쪽과 오른쪽으로 나누어서 탐색을 수행해야한다.
실제로 [2,4]와 [5,6]의 합이 [2,6]이 될건데 [2,4]는 왼쪽에 있고 [5,6]은 오른쪽에 있어
3-4) 네번째로는 [left,right]와 [start,end]가 서로 일부가 겹쳐져 있는 경우이다.
이 경우는 3-3)과 사실상 똑같다
마찬가지로 해당 노드에서 왼쪽, 오른쪽으로 나누어 탐색해야한다
다시 [2,6]에 존재하는 구간의 합을 묻는데 처음 [0,9]는 3-3)의 경우에 해당되어 왼쪽과 오른쪽으로 나누어 탐색하는데..
왼쪽의 [0,4]는 [2,6]과의 관계를 살펴보면 서로 일부가 겹쳐져있는 경우잖아.
그래서 다시 왼쪽과 오른쪽으로 나누어 탐색한다
그래서 [2,6]이 완전히 포함하고 있는 [start,end]를 찾을때까지 내려가겠지?
왼쪽의 경우에는 2랑 [3,4]를 찾아갈거고 오른쪽의 경우에는 [5,6]을 찾아가겠네

4. 예시로 이해해보는 구간의 합 구하기
다음과 같은 segment tree에서 [3,9]에 존재하는 수의 합을 구하고 싶다면...?
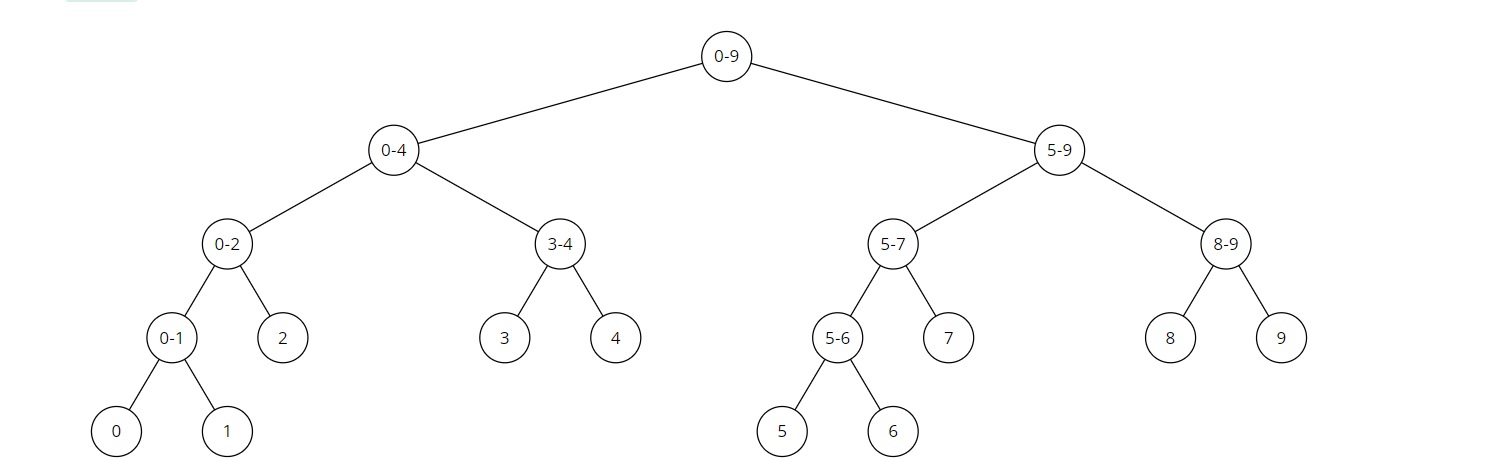
먼저 루트 노드를 탐색한다
루트 노드는 [0,9]인데, [3,9]가 포함되므로 왼쪽 자식과 오른쪽 자식으로 나누어 탐색하게 된다

다시 왼쪽의 [0,4]는 [3,9]와 일부가 겹쳐지므로 왼쪽과 오른쪽으로 나누어 탐색하게 된다

다시 왼쪽의 [0,2]는 [3,9]와 완전히 벗어났으므로 더 이상 탐색하지 않고 0을 return
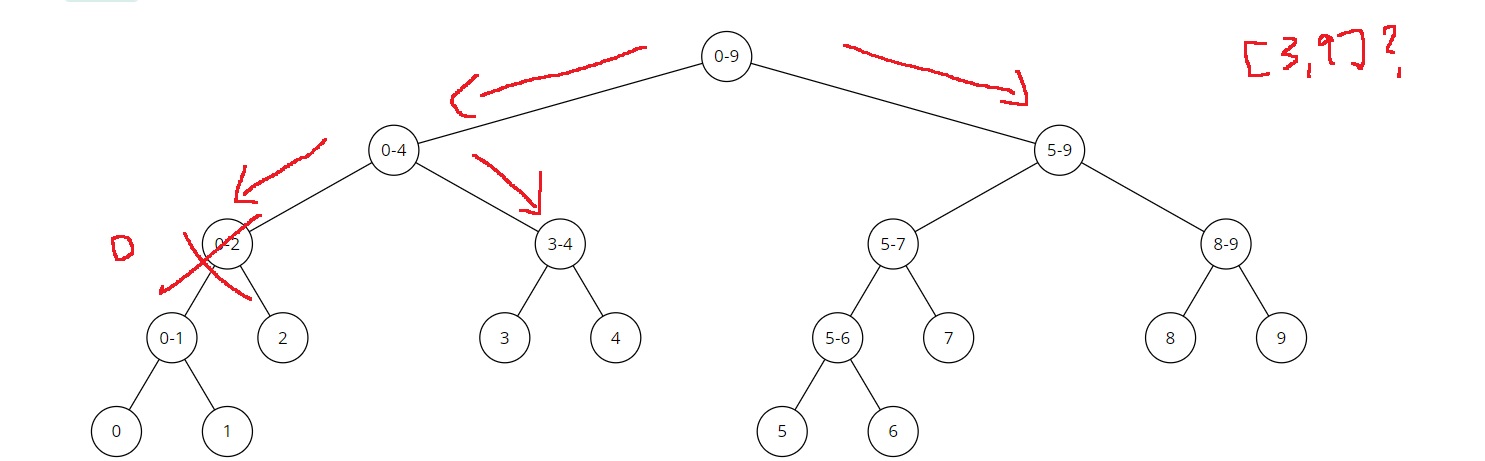
오른쪽의 [3,4]는 [3,9]에 완전히 포함되고 있으므로, 해당 노드에 저장된 값을 가져오고 더 이상 탐색하지 않는다

다음 오른쪽의 [5,9]는 [3,9]에 완전히 포함되고 있으므로 더 이상 탐색하지 않고 해당 노드에 저장된 값을 가져온다

따라서 세그먼트 트리는 [3,4]의 값과 [5,9]의 합을 구해서 [3,9]의 합을 구해준다
5. 구현 예시 - 구간의 합을 구하는 방법
결국 첫번째 경우와 두번째 경우 그리고 그 이외의 경우로 나눌 수 있다
[left,right]가 완전히 벗어나면 0을 return하고
[left,right]가 [start,end]를 완전히 포함하면 해당 노드의 값을 가져오고
그 이외의 경우에는 왼쪽과 오른쪽으로 나누어서 구한다
#tree, tree의 인덱스
#[start,end]는 해당 트리 인덱스가 저장하는 구간
#[left,right]는 합을 구하고 싶은 구간
#최초에 tree_index = 1, start = 0, end = N-1(배열 A의 크기 N)
def query(tree, tree_index, start, end, left, right):
#[left,right]가 [start,end]를 완전히 벗어난 경우
#탐색할 필요도 없고 값을 가져올 필요도 없다
if left > end or right < start:
return 0
#[left,right]가 [start,end]를 완전히 포함하는 경우
#해당 노드에 저장된 값을 가져오고 더 이상 탐색할 필요는 없다
if left <= start and end <= right:
return tree[tree_index]
#그 이외의 경우
#왼쪽 자식과 오른쪽 자식으로 나누어서 탐색
#부모 인덱스가 tree_index라면... 왼쪽 자식은 2*tree_index, 오른쪽 자식은 2*tree_index+1
mid = (start + end) // 2
left_answer = query(tree,2*tree_index, start, mid, left, right)
right_answer = query(tree,2*tree_index+1, mid+1, end, left, right)
return left_answer + right_answer
맞게 했는지.. 아닌지 검증을 해봐야겠지
tree_index에는 최초에 1을 넣어주고
start, end에는 최초에 0, N-1을 넣어준다(N은 배열 A의 크기)
[3,9]는 실제로 49인데 위 그림에서도 [3,4]는 9이고 [5,9]는 40이라 49이고
실제로 구해봐도 49가 나옴

6. 시간복잡도
배열 A의 크기가 N일때, 세그먼트 트리의 높이 $h= \left \lceil log_{2} N \right \rceil $로 구해지므로
수열의 구간합을 구할때 시간복잡도는 O(logN)이다.
직관적으로 logN개만 탐색하면 구간합을 구한다는 뜻이지
7. 연습문제
세그먼트 트리가 필요없지만... 제대로 구현된건지 검증해볼까?
11659번: 구간 합 구하기 4 (acmicpc.net)
11659번: 구간 합 구하기 4
첫째 줄에 수의 개수 N과 합을 구해야 하는 횟수 M이 주어진다. 둘째 줄에는 N개의 수가 주어진다. 수는 1,000보다 작거나 같은 자연수이다. 셋째 줄부터 M개의 줄에는 합을 구해야 하는 구간 i와 j
www.acmicpc.net
생성하는데 시간이 좀 걸리나봐... 오히려 prefix sum보다 느리다
import math
from sys import stdin
def create_segment(A,tree,tree_index,A_start,A_end):
if A_start == A_end:
tree[tree_index] = A[A_start]
else:
A_mid = (A_start+A_end)//2
create_segment(A,tree,2*tree_index,A_start,A_mid)
create_segment(A,tree,2*tree_index+1,A_mid+1,A_end)
tree[tree_index] = tree[2*tree_index] + tree[2*tree_index+1]
def query_sum(tree,tree_index,start,end,left,right):
if left > end or right < start:
return 0
if left <= start and end <= right:
return tree[tree_index]
mid = (start+end)//2
left_sum = query_sum(tree,2*tree_index,start,mid,left,right)
right_sum = query_sum(tree,2*tree_index+1,mid+1,end,left,right)
return left_sum+right_sum
N,m = map(int,stdin.readline().split())
A = list(map(int,stdin.readline().split()))
n = 2**(math.ceil(math.log2(N))+1) - 1
tree = [0]*(n+1)
create_segment(A,tree,1,0,N-1)
for _ in range(m):
left,right = map(int,stdin.readline().split())
print(query_sum(tree,1,0,N-1,left-1,right-1))
참조
세그먼트 트리
누적 합을 사용하면, 1번 연산의 시간 복잡도를 $O(1)$로 줄일 수 있습니다. 하지만, 2번 연산으로 수가 변경될 때마다 누적 합을 다시 구해야 하기 때문에, 2번 연산의 시간 복잡도는 $O(N)$입니다.
book.acmicpc.net
41. 세그먼트 트리(Segment Tree) : 네이버 블로그 (naver.com)
41. 세그먼트 트리(Segment Tree)
이번 시간에 다룰 내용은 여러 개의 데이터가 연속적으로 존재할 때 특정한 범위의 데이터의 합을 구하는 ...
blog.naver.com
Binary tree - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Limited form of tree data structure Not to be confused with B-tree. A labeled binary tree of size 9 and height 3, with a root node whose value is 1. The above tree is unbalanced and no
en.wikipedia.org
'알고리즘 > 세그먼트 트리' 카테고리의 다른 글
| 파이썬 알고리즘 기본기 곱셈 연산에서 주의할 점 배우기(세그먼트 트리 문제) (0) | 2022.12.10 |
|---|---|
| 세그먼트 트리 응용2 -최솟값과 최댓값을 구하는 세그먼트 트리- (0) | 2022.12.08 |
| 세그먼트 트리 응용1 - 구간의 곱을 구하는 세그먼트 트리 (0) | 2022.12.06 |
| 고난이도 자료구조 세그먼트 트리 구현하면서 이해하기 3편(값을 업데이트 하는 방법) (0) | 2022.12.05 |
| 고난이도 자료구조 세그먼트 트리 개념 이해하기 1편 (0) | 2022.12.05 |