


중심단어 기준으로 몇개의 단어를 볼지 그 범위를 window라고 한다.
왜 헷갈리기 시작했냐면 중심단어가 무조건 하나만 있다고 생각이 고정되어버리는 거임
예측하고자 하는 중심단어는 선택할 수가 있다.
무슨말이냐면 "The fat cat sat on the mat" 이 문장이 입력으로 주어졌다고 생각해보자.
근데 이제 그냥 중심단어를 무조건 sat이라 하고 window size=3이라 해서
나머지 {"The", "fat", "cat", "on", "the", "mat"}가 주변단어라고 해버리니까 생각이 멈춰버리는거임..
모델이 embedding vector를 구하는게 목적이라고 생각한다면
모든 단어에 대해서 embedding vector를 구해야할거 아니냐
그러니까 모든 단어가 중심단어가 될 수 있다는 것임.
이것이 바로 sliding window기법이다.
output으로 원하는 중심단어를 선택하고 지정한 window만큼 이동하여
model 학습을 위한 데이터셋을 만드는 과정이다.
1. CBOW
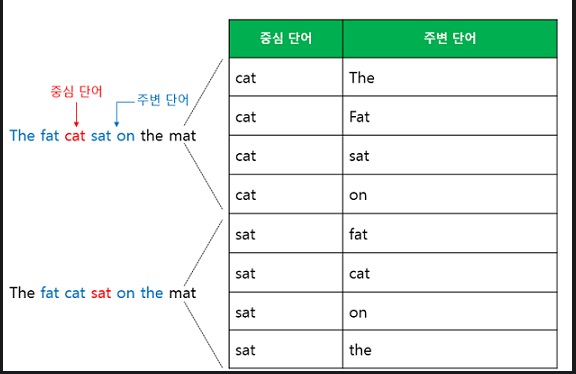
CBOW를 예로 들어 그림을 보자.

window size가 n이면 중심단어와 주변단어는 어떤 관계를 가질까? 주변단어는 2n개가 된다.
2*window size만큼 된다는 것이다.
코드 구현에서 왜 2*window size에 집착했는지 이제는 알 수 있을 것이다.
위 그림의 표가 바로 CBOW의 훈련데이터 세트가 된다.
2. CBOW의 데이터셋 구현
from tqdm import tqdm
import torch
class CBOWDataset(Dataset):
def __init__(self, train_tokenized, window_size=2):
self.x = []
self.y = []
for tokens in tqdm(train_tokenized):
token_ids = [w2i[token] for token in tokens]
for i,id in enumerate(token_ids):
if i - window_size >= 0 and i + window_size < len(token_ids):
self.x.append(token_ids[i - window_size:i] + token_ids[i+1: i + window_size+1])
self.y.append(id)
self.x = torch.LongTensor(self.x) #(전체 데이터 개수, 2 * window_size)
self.y = torch.LongTensor(self.y) #(전체 데이터 개수)
def __len__(self):
return self.x.shape[0]
def __getitem__(self,idx):
return self.x[idx], self.y[idx]
왜 입력 x가 2*window size인거 알겠지? 주변단어가 그만큼 생성되니까 그렇다.
from torch import nn
class CBOW(nn.Module):
def __init__(self, vocab_size,dim):
super(CBOW,self).__init__()
self.embedding = nn.Embedding(vocab_size,dim,sparse=True)
self.linear = nn.Linear(dim, vocab_size)
#B: batch size, W: window size, d_w: word embedding size, V: vocab_Size
def forward(self,x): #x:(B,2W)
embeddings = self.embedding(x) # (B,2W,d_w)
embeddings = torch.sum(embeddings,dim=1) #(B,d_w)
output = self.linear(embeddings) #(B,V)
return output클래스의 입력 사이즈에도 왜 2w인지 알겠지.. 입력이 2w만큼 들어가거든
참고로 embedding의 sum을 torch.sum()으로 했다는 점 주목할 만하다.
원래 논문의 방식을 따랐다고 한다.
3. Skip-gram
비슷하게 skip gram의 경우 훈련데이터 세트는 다음과 같이 구성된다.
혹은 하나 하나 차분하게 살펴보고 싶으면
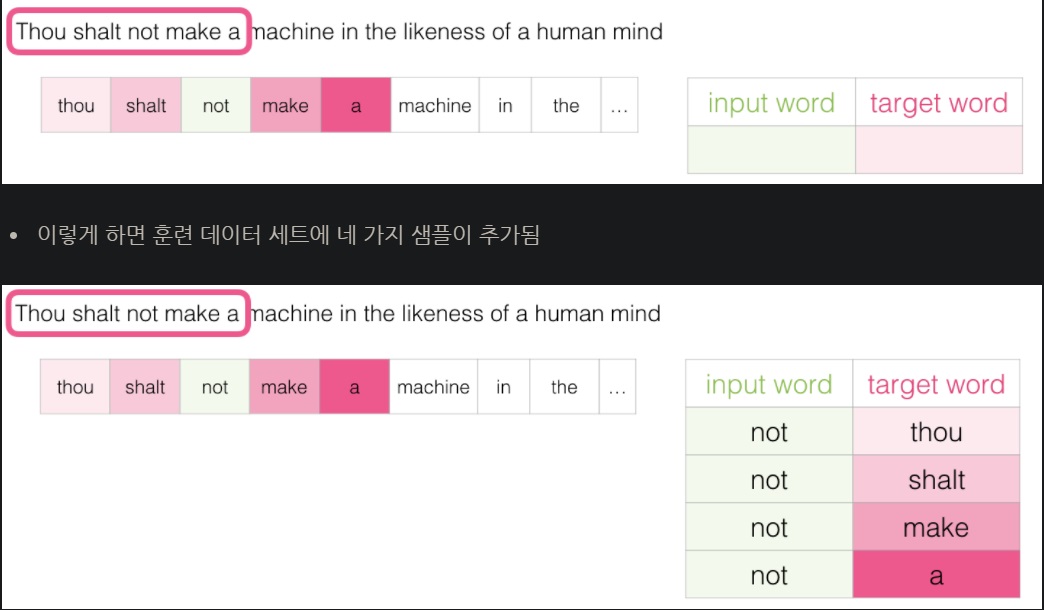
4개 sample 추가
니가 여기서 착각한점은 not이 하나만 있고 나머지 주변단어 4개에 대응된다는 점인데
그러니까 데이터세트에 2*window size가 도저히 이해가 안되는거임
중심단어 하나 주변단어 하나 이렇게 넣어야 되니까 중심단어가 2*windowsize만큼 늘어남
아무튼 window를 이동해서
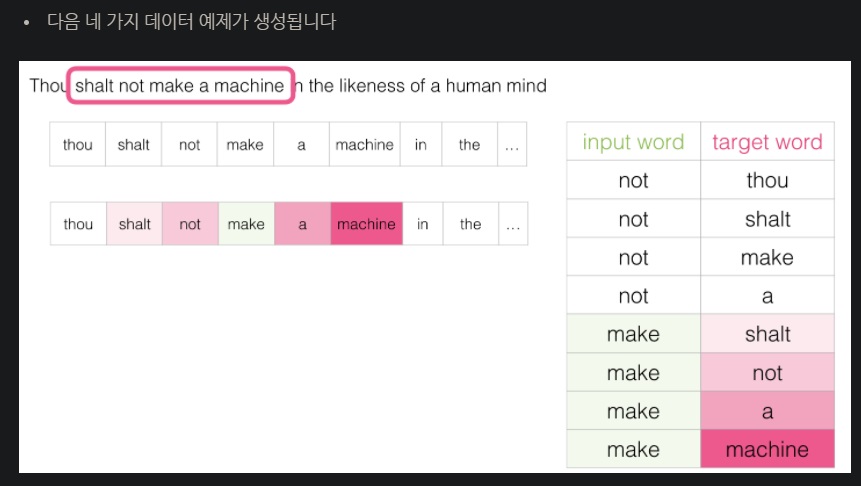
마지막으로
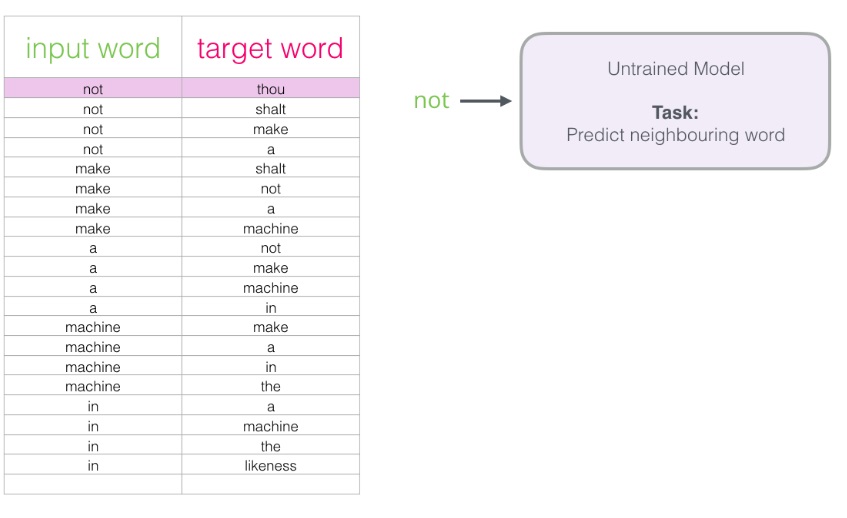
이런 skip gram의 훈련데이터셋을 얻는다
그럼 이제 skip gram의 데이터셋 코드도 이해할 수 있겠지?
from torch.utils.data import Dataset
from tqdm import tqdm
class SkipGramDataset(Dataset):
def __init__(self, train_tokenized, window_size = 2):
self.x = []
self.y = []
for tokens in tqdm(train_tokenized):
token_ids = [w2i[token] for token in tokens]
for i, id in enumerate(token_ids):
if i - window_size >= 0 and i + window_size < len(token_ids):
self.y += (token_ids[i - window_size:i] + token_ids[i+1:i + window_size+1])
self.x += [id] * 2 * window_size
self.x = torch.LongTensor(self.x) #(전체 데이터 개수)
self.y = torch.LongTensor(self.y) #(전체 데이터 개수)
def __len__(self):
return self.x.shape[0]
def __getitem__(self,idx):
return self.x[idx],self.y[idx]
왜 x에 2*windowsize가 붙었을까? 주변단어수가 2*windowsize만큼 있고 각각에 중심단어를 대응시키니까 그렇다
그러면 클래스코드를 보면
from torch import nn
import torch
class SkipGram(nn.Module):
def __init__(self, vocab_size,dim):
super(SkipGram, self).__init__()
self.embedding = nn.Embedding(vocab_size, dim, sparse=True)
self.linear = nn.Linear(dim,vocab_size)
#B: batch size, W: window size, d_w: word embedding size, V: vocab size
def forward(self, x): # x:(B)
embeddings = self.embedding(x) #(B, d_w)
output = self.linear(embeddings) #(B,V)
return output
입력으로 한 단어가 여러개 배치만큼 들어가잖아

CBOW는 여러 단어가 들어가니까 2W로 추가 랭크가 있었고
결과는 이제 주변단어들 수만큼이니까 VOCAB SIZE로 나오는거임
'딥러닝 > NLP' 카테고리의 다른 글
| GRU(gated recurrent unit)와 LSTM의 backpropagation에 대하여 (0) | 2022.03.20 |
|---|---|
| RNN을 개선한 LSTM과 GRU 구조 알아보기 (0) | 2022.03.16 |
| RNN의 기본 구조 이해하기 (0) | 2022.02.19 |
| Word2Vec의 2가지 형태 - CBOW와 skip-gram 모델 (0) | 2022.02.15 |
| text를 embedding시키는 Word2Vec의 성질 이해하기 (0) | 2022.02.11 |