

1. character embedding
character level의 경우 아스키코드로 0~255사이 값으로 mapping하여 코딩하는 경우 있지만
machine learning 관점에서는 오히려 사용하기 까다로울수 있다??
몰랐는데 CNN을 이용하여 character embedding을 하는 경우도 많은 것 같음
underestimate가 과소평가하다라는 뜻인데 misunderestimate는 실제 없는 단어지만
mis와 underestimate의 합성어로 잘못 과소평가하다라는 뜻으로 추측할 수 있음
이런 인간의 언어 능력을 흉내내기 위해 character embedding을 연구하고 있다고는 함
2. word embedding
근데 보통은 word level에서 embedding하는 경우가 많다
오디오는 1d signal waveform, 이미지는 2d signal인데 word는 이런 표현이 쉽지 않다
text는 embedding vector라는 dense vector로 표현
multi-dimensional한 실수값 갖는 벡터형태
각 dimension이 어떤 의미같은 것을 가리킬것이라고 distribution feature vector식으로 표현함
물론 dimension의 의미가 명확히 해석이 가능하다는 식으로 존재한다는 것은 아니다

각 dimension의 의미로 living being, human 등이 표시되어있지만 명확히 해석 가능한 것은 아니다.
3. word embedding의 generalization power
multidimensional word embedding vector을 2차원으로 축소하여 표시하면
단어의 의미가 비슷한 word embedding vector은 비슷한 위치에 표시된다.

kitten과 cat은 의미가 비슷해서 가까운 위치에 있다.
dog는 cat/kitten과는 가깝고 house와는 거리가 멀다.
man과 woman의 차이를 나타내는 벡터를 king에 더하면 놀랍게도 queen에 매칭된다.
두 단어 사이에 내재하는 본질적인 의미관계를 정확히 학습했다는 것

man과 woman사이의 의미차이와 queen과 king사이 의미차이가 유사하다
4. skip gram model
중심단어의 주변 N개 word를 예측하는 학습 모형
그러면서 word와 word사이 관계성을 자연스럽게 학습

window size=5일때 중심단어(파란색) 주변의 4개의 단어를 모아서 training sample로 구성
(중심단어, 주변단어1), (중심단어, 주변단어2), … , (중심단어, 주변단어 4)
sliding window로 stride를 통해 중심단어를 바꿔가면서 training sample을 하나의 문장내에서 많이 모아
사실 최종목표는 word를 예측하는 것이 아니고 이 과정에서 word embedding vector를 얻기 위한 두 가중치 W와 W’을 학습
가중치 W의 각 행이 대응하는 word의 embedding vector

$x_{k}$를 input으로 넣어 $x_{k}$ 주변의 단어 $y_{1,j}, y_{2,j}, y_{3,j}$를 예측하는 모형
그러나 목적은 이 과정에서 학습되는 가중치 W, W’을 구하는 모형
$x_{k}$가 one hot vector이므로 W와 곱하면 $x_{k}$의 원소가 1인 곳에 대응하는 W의 row가 hidden vector로 들어가므로
W의 각 행이 word embedding이 될 수 있다.
5. image and text joint embedding
5-1) motivation
서로 다른 modal의 데이터를 match하기 위한 공통된 공간의 embedding을 학습하는 방법
pretrained unimodal을 사용하여 unimodal은 학습하지 않고 joint embedding space를 학습하는 것을 목표로함
5-2) image tagging
주어진 이미지(image)의 태그(text)를 생성하거나 태그를 이용해 이미지를 검색하는 방법

5-3) idea
pretrained text unimodal model과 image unimodal model을 합쳐서 구현함
각 unimodal에서 뽑은 vector를 같은 space로 들어갈수 있도록 동일한 차원의 vector로 바꿔주는 작업이 필요

text model(word2vec 등)에서 embedding vector
image model(CNN 등)에서 feature vector
각 vector의 차원이 동일하도록 중간에서 바꿔주고 동일한 공간으로 들어감
5-4) metric learning
distance 기반으로 두 feature vector사이 거리를 조절하는 방식으로 학습하는 것
joint embedding space로 들어온 text vector와 image vector는 서로 관계가 있다면
두 vector 사이의 distance(=similarity)를 줄이도록 학습을 함
visual data와 text data가 서로 호환되는 joint visual-text embedding space가 학습이 됨

joint embedding space로 들어온 text와 image vector가 관계가 있다면 distance를 줄이고
관계가 없다면 distance를 늘려서 학습을 함
5-5) property
Word2Vec에서 보여줬던 두 embedding vector 사이의 의미관계 학습한 것을 그대로 보여줌
joint embedding space에서 학습한 image vector A에서 대응하는 word vector A를 빼고
전혀 다른 새로운 word vector B를 더해준 뒤 얻은 joint embedding vector와 유사한 image joint embedding vector를 찾아보면
word vector B에 대응하는 이미지들이 나옴

dog image에서 dog vector를 빼면 image vector에서 dog정보가 빠져나가는거
거기에 cat word vector를 더해주면 image에 cat이 그려지는거지
재밌는 부분은 top1 image에서 배경이 꽤 비슷하게 유도(2번째 4번째는 아닌거보면 약간 억지긴한데)
5-6) image food recipe retrieval
음식 이미지를 넣으면 이미지 내의 음식을 만드는 recipe가 text로 출력
joint embedding이니까 반대로 recipe를 넣으면 만들어지는 음식의 이미지를 출력

image tagging에서 tag는 단순히 word였지만 recipe는 word의 나열인 sequence data
recipe 내에서 재료를 넣는 순서대로 RNN에 sequence data로 넣어 ingredient vector를 encoding
음식을 만드는 지시사항을 순서대로 RNN에 sequence data로 넣어 instruction vector를 encoding
두 vector를 concatenation하고 fully connected layer에 통과하여 fixed dimensional vector로 text modal의 vector를 만들어냄
fully connected layer를 통과하는 이유는 joint embedding을 위해서 image modal의 vector와 차원이 동일하게 만들어주기 위해서다.

반대로 image modal에서 feature vector를 뽑아내고 joint embedding을 위해서
text modal의 vector와 동일한 차원으로 맞춰주는 fully connected layer를 통과시켜 최종 image vector를 뽑아냄
두 modal에서 뽑은 vector사이 cosine similarity loss로 image와 recipe가 연관성이 있으면 loss를 줄이는 방향으로 학습을 진행

cosine similarity loss로 unimodal에서 뽑은 image vector와 text vector사이 연관성을 학습
근데 여기서 끝이 아니다.
recipe와 food image가 high level에서 동일한 category에 속하도록 만들기 위해 semantic regularization loss를 도입했다.

두 recipe vector와 food image vector를 동일한 fully connected layer에 각각 넣어서 얻은 hidden vector를 이용하여 semantic regularization loss를 계산
food image와 recipe가 동일한 category에 속하면 loss를 줄이는 방향으로 학습
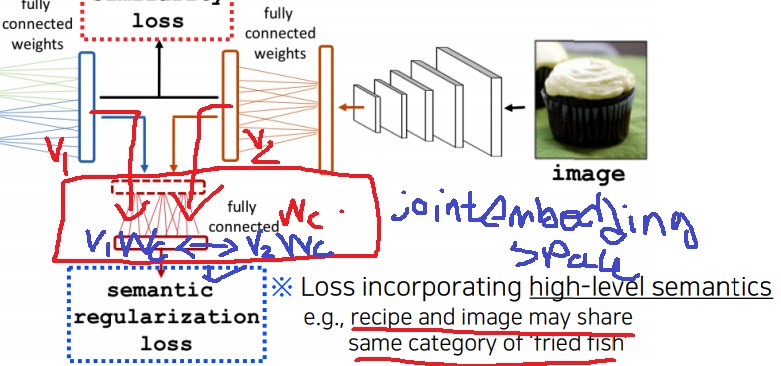
image tagging에서 joint embedding space의 metric learning을 하는 방식이랑 비슷한듯??
'딥러닝 > Computer Vision' 카테고리의 다른 글
| test time augmentation (0) | 2024.04.02 |
|---|---|
| multimodal learning2 - show, attend and tell, visual question answering - (0) | 2023.07.05 |
| multimodal learning의 기본 개념, 왜 어려운 문제인가? (0) | 2023.07.03 |
| GAN loss의 단점을 극복하기 위한 Perceptual loss (0) | 2023.07.01 |
| 서로 관련없는 이미지로 바꿔버리는 CycleGAN의 핵심 아이디어 (0) | 2023.06.30 |