

1. 유튜브 추천 시스템, 딥러닝을 도입하다
행렬 인수분해 기법은 딥러닝의 구조와 많이 닮아있습니다.
결과를 도출하기 위해 내재된 특성을 찾아 여러 차례 게산하는 구조가 마치 인공 신경망을 이용해 여러 차례 계산해나가는 과정과 비슷하죠
행렬 인수분해는 중간 구조가 없는 간결한 형태의 신경망 구조를 띠는 반면 딥러닝은 중간 구조가 깊은 신경망 구조를 보여줍니다.
이처럼 유사한 구조로 인해 최근에는 행렬 인수분해 대신 딥러닝으로 접근하려는 시도가 많이 있습니다.
2016년 공개된 유튜브의 추천 시스템도 행렬 인수분해를 딥러닝으로 바꿔서 더 좋은 성능을 낸 구조였죠.
깊은 신경망일수록 더 좋은 성능을 냈습니다.
물론 딥러닝이 제대로 성능을 내기 위해서는 엄청난 데이터가 필요하지만, 이미 유튜브에는 2019년에만 1분에 500시간이 넘는 비디오가 업로드될 정도로 방대한 데이터가 매일 쌓이고 있습니다.
2006년에 넷플릭스가 넷플릭스 프라이즈를 진행할 때도 이미 1억건이 넘는 평가 데이터를 공개했을 정도죠.
빅데이터 시대에 접어들면서 많은 기업이 고객의 평점 기록 같은 중요한 데이터를 축적했기 때문에 이제 이들 데이터가 빛을 발할 때가 온 거죠.
성능을 높이기 위해 추가 정보도 활용할 수 있습니다.
지금까지 단순히 평점 데이터만 가지고 고객과 영화의 관계를 유추했다면, 평점 외에도 고객의 성별, 나이 같은 개인정보, 영상 길이, 제작국, 언어 같은 영화 정보까지 함께 입력값으로 활용하면 훨씬 더 성능이 좋은 모델을 만들어낼 수 있죠
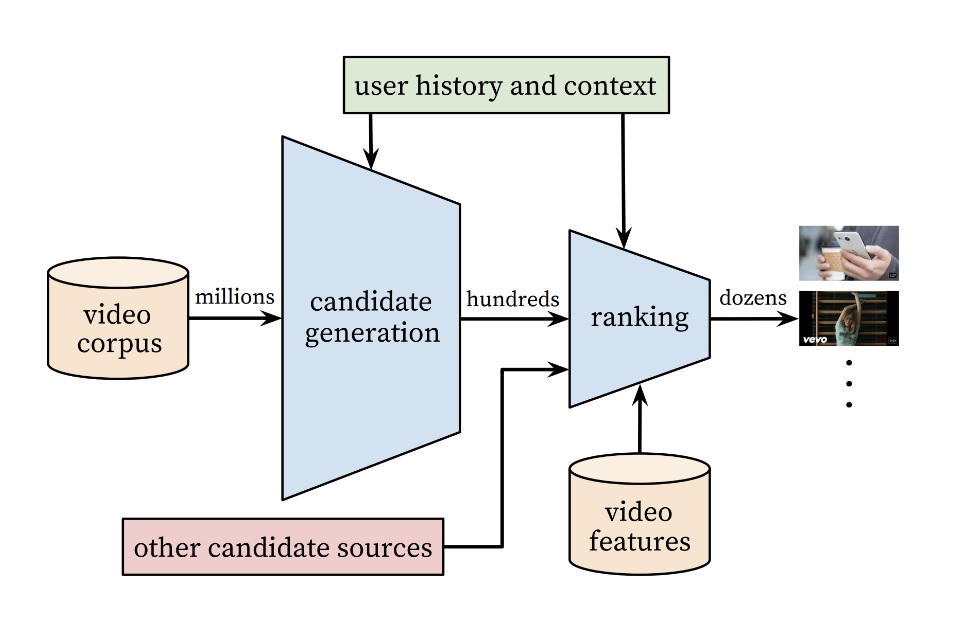

실제로 유튜브가 2016년에 공개한 추천 시스템 논문에 따르면 유튜브의 추천 시스템은 다양한 특징을 결합한 딥러닝 모델이었습니다.
그전까지도 유튜브도 행렬 인수분해를 사용했지만, 2016년을 전후해 딥러닝 모델을 점차 도입한거죠.
여기에는 평가 정보 외에도 고객의 성별, 거주국, 시청기록, 이전 노출 목록, 마지막 시청 후 경과 시간 같은 고객 정보를 비롯해 영상 길이, 조회 수, 영상 제작 시점 등 영상에 대한 다양한 정보까지 입력값으로 활용해 최종 결과를 예측해냈습니다.
뿐만 아니라 편향을 줄이기 위해 유튜브 이외의 영상을 시청한 이력도 확인했습니다.
앞서 사용자가 유튜브에서 시청하는 영상 중 70%는 알고리즘이 추천한 영상이라고 했죠
따라서 유튜브 영상만으로 시청 기록을 학습하면 70%확률로 추천한 영상을 다시 학습하는 문제가 생깁니다.
이 같은 편향을 줄이기 위해 유튜브는 유튜브 밖에서 시청한 이력도 모두 활용한 거죠.
이처럼 유튜브는 편향까지 없애기 위해 수많은 정보를 종합적으로 고려했고 그 결과가 우리에게 막 시청을 마친 영상 뒤에 올라옵니다.
유튜브는 초창기에 영상을 추천하는 데 어떤 가치를 극대화할지 고민을 거듭했다고 합니다.
초기에는 조회 수를 올리는 데만 방향이 맞춰져있었죠. 그러다 보니 크리에이터들이 유익한 영상보다는 온통 자극적인 섬네일을 만들어내는 데 치중했습니다.
영상을 클릭한 사람들이 낚인 걸 알고 즉시 빠져나와도 이미 조회 수는 올라간 뒤였죠
이후 유튜브는 사람들이 오래 시청하는 영상을 추천하도록 보상함수를 개선했다고 밝힙니다.
뿐만 아니라 "이어 보기"에도 매우 높은 가중치를 부여했죠.
보상은 기존처럼 "많이 클릭"하는 게 아니라 "덜 클릭하고, 더 오래보는" 영상에 집중되었고, 실제로 영상의 품질을 높이는데 많은 도움이 되었습니다.
2. 새로운 영상은 어떻게 추천해야하는가
또한 유튜브는 신선도를 무척 강조합니다. 4장에서 "최신 문서"의 중요성을 강조한 것처럼 새로 올라온 영상일수록 고객의 관심이 높기 때문이죠
뉴스, 영화, 유튜브 모두 소위 "신상"이 매우 중요한 콘텐츠입니다. 하지만 새로운 영상은 영상에 관한 아무런 정보가 없는 콜드 스타트 문제에 봉착합니다.
콜드 스타트(cold start)는 말 그대로 차갑게 시작한다는 뜻으로 새로 올라온 영상일수록 조회 수도 없고, 인기 있을지 알아낼 만한 정보가 거의 없어서 추천 영상에 올라가기가 매우 어렵습니다.
올림픽에 육상 선수를 내보내야 하는데, 선수들이 달리는 모습을 보지도 못한 채 신체 조건만 보고 출전 선수를 골라내야 하는 상황과 비슷합니다.
수많은 선수 중에 누가 우사인 볼트인지 찾아낼 수 있을까요?
고객들은 무엇보다 새로운 영상을 좋아합니다.
하지만 새로울수록 정보가 부족하기 때문에 추천이 더 어려워지는 역설적인 상황에 놓입니다.
추천 시스템은 이 문제를 해결해야 하죠.
마치 점쟁이처럼 영상의 몇 가지 특징만 가지고 불특정 다수에게 추천할 수 있어야 합니다. 정말 어려운 일이죠
영상 뿐만 아니라 고객도 마찬가지입니다.
신규 고객의 관심사를 예측하기도 정말 어려운 일이죠. 넷플릭스도 초창기에 그리고 왓챠도 가입을 하면 굳이 선호하는 영화를 몇 가지 택하도록 합니다.
신규 고객의 선호도를 미리 파악하여 정교한 추천을 시작하기 위해서죠.
아무런 고객의 정보가 없다면, 무엇을 추천해야 좋을지 도무지 감을 잡기 어렵습니다.
로맨스를 좋아하는 고객에게 갑자기 공포 영화를 추천하면 그 서비스에 첫인상이 좋지 않을 겁니다.
이외에도 추천시스템은 고객이 기존 취향의 울타리 안에만 갇히지 않도록 노력합니다.
협업 필터링이 어느 정도 관심사를 확장하는 효과를 내긴 하지만 이 또한 성향이 비슷한 고객만 구독하게 된다면, 다른 성향의 고객이 좋아하는 콘텐츠는 알 길이 사라지죠.
보수적인 성향의 사용자가 보수적인 취향을 지닌 사람만 구독하면 항상 비슷한 우파 영상을 추천받게 되겠죠
이는 진보적인 성향도 마찬가지입니다. 결국 서로가 단절되고, 우물 안 개구리처럼 편견을 강화할 뿐입니다.
이는 사회적으로 매우 위험한 문제로 번질 수도 있습니다.
그래서 뜻밖의 발견(serendipity)이 중요합니다. 멋진 영어 단어이자 설레는 표현이기도 하죠.
여기에는 2가지 조건이 충족되어야 합니다. 지금까지 본 적 없는 것이지만 희한하게도 마음에 들어야 하죠.
다시 말해 나에게 편하고 익숙한 구역 바깥에 있어야하지만, 또 아예 엉뚱하지는 않아야합니다.
참, 어렵죠. 하지만 사람들이 "알 수 없는 알고리즘이 여기로 이끌었다"라고 자주 감탄하는 것은 그래도 이 2가지 조건을 종종 만족하고 있다는 거겠죠?
친구가 나에게 뜻밖의 영화를 소개해줬는데 너무 만족스러워 하루 종일 즐겁던 기억이 있지 않나요?
추천 시스템의 목표가 바로 이것입니다. 우리가 "뜻밖의 발견"으로 설렐 수 있게 앞으로도 추천 시스템은 "알 수 없는 알고리즘"을 꾸준히 만들 거에요.

'책 읽기 > 비전공자도 이해할 수 있는 AI지식' 카테고리의 다른 글
| 비전공자도 이해할 수 있는 AI지식 -컴퓨터가 글을 읽는 방법- (0) | 2022.12.08 |
|---|---|
| 비전공자도 이해할 수 있는 AI지식 -컴퓨터는 어떻게 사람의 목소리를 이해하는가- (0) | 2022.12.07 |
| 비전공자도 이해할 수 있는 AI지식 -잠재요인을 찾아내는 추천시스템- (0) | 2022.12.01 |
| 비전공자도 이해할 수 있는 AI지식 -나와 취향이 비슷한 사람이 본 것을 추천해준다- (0) | 2022.11.15 |
| 비전공자도 이해할 수 있는 AI지식 -추천시스템의 밑바탕에는 장바구니분석이 있었다- (0) | 2022.11.15 |