

1. 개요
가중치가 있는 무방향 그래프에서 최소 신장 트리를 찾는 대표적인 알고리즘 중 하나이다.
크루스칼 알고리즘이 간선들을 선택해가면서 최소 신장 트리를 구성하는 반면에 프림 알고리즘은 정점을 선택하고,
인접한 정점 중에서 최소 비용을 가지는 간선을 하나씩 선택해가면서 최소 신장 트리를 구성하는 일종의 그리디 알고리즘이다.
다익스트라 알고리즘과 사실상 동일한 알고리즘이다.
참고로 다익스트라 알고리즘은 음수 가중치에서는 동작하지 않지만, 프림 알고리즘은 음수 가중치에서도 동작한다고 한다
2. 알고리즘
2-1) 임의의 정점을 하나 선택해서 최초의 트리를 구성
2-2) 선택한 정점과 트리에 포함된 정점들과 인접한 정점중 최소 비용의 간선이 존재하는 정점을 선택한다
2-3) 모든 정점이 선택될 때까지 위 과정을 반복한다
위 알고리즘은 항상 최소 신장 트리의 최적해를 보장한다.
3. 예시를 통해 이해하는 프림 알고리즘
다음 그래프에서 프림 알고리즘을 이용해 최소 신장 트리를 찾아보자.

최초 0번 노드를 임의로 선택하고, 인접한 정점들 간의 비용을 고려해본다.

0번 노드 간의 인접한 간선은 (0,5), (0,1), (0,2), (0,6)으로 4가지이다. 여기서 최소 비용은 (0,2)로 31이다.
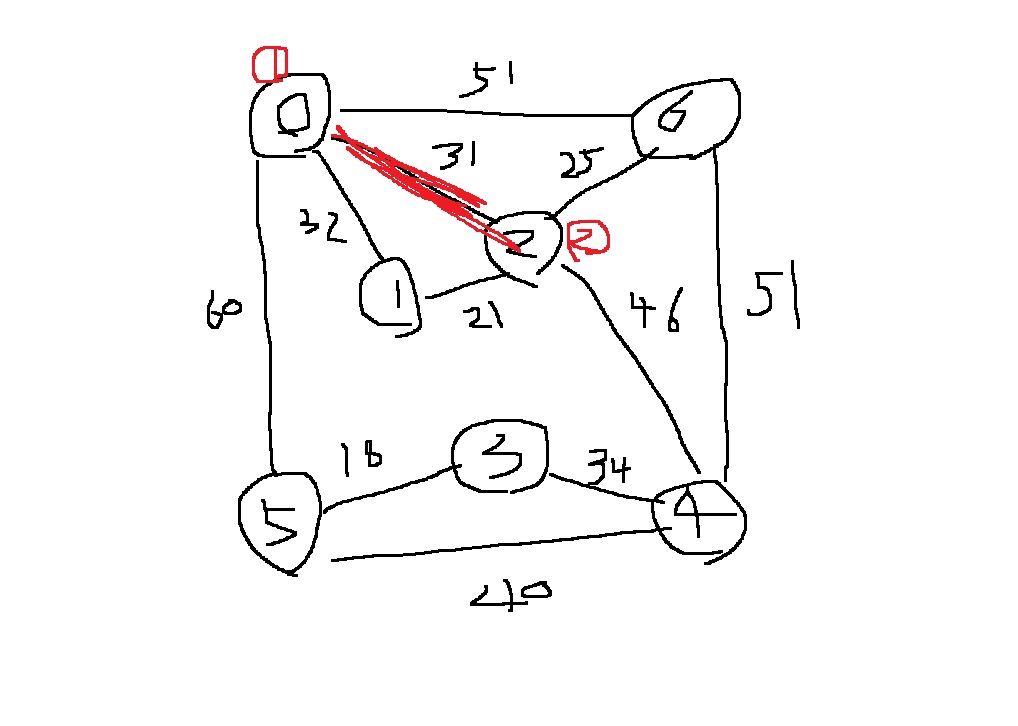
다음으로 2와 인접한 정점인 1,6,4 사이 간선 (2,1), (2,6), (2,4)의 비용 21,25,46을 비교하여 최소 비용을 가지는 간선을 고른다.
그것은 (2,1)이므로..

다음으로 0,1,2와 인접한 노드들 간 최소 비용을 가지는 간선을 골라야하는데...
(0,1)은 0-1-2 사이 사이클이 발생하므로 신장 트리의 조건에 맞지 않다.(사이클이 발생하지 않아야함)
그러므로 다음 최소 비용인 25를 가지는 (2,6)을 선택한다.

다음으로 트리에 포함된 0,1,2,6과 인접한 노드들 간 최소 비용인 46을 가지는 (2,4)를 선택한다

다음으로 0,1,2,4,6과 인접한 노드들 간 최소 비용을 가지는 간선은 (3,4)인 34이므로.. 이것을 선택

마지막으로 (3,5)가 최소 비용 18이므로 이것을 연결하면 최소 신장 트리 완성

4. 프림 알고리즘 기본형 구현 예시
기본 형태는 $O(V^{2})$으로 알려져있다.. 정점의 개수가 많아지면 매우 느리다는 소리
보면 알겠지만 for _ in range(v): ~~ for i in range(v+1): + for w in range(v+1):로 $O(V^{2})$이네
핵심은 정점에 대하여 MST 포함 여부를 만들고
MST에 포함되지 않고 최소 가중치를 가지는 정점을 선택하여 MST에 포함시키고
포함된 정점과 인접하면서 MST에 포함되지 않은 정점을 선택하여 연결시키고, key값을 갱신해나가 모든 key를 찾는다
인접행렬 사용 가능하면, 이 알고리즘이 매우 빠르다
def prim(r,v): ##임의로 고른 시작 정점 r, 마지막 정점 v
MST = [0]*(v+1) ##정점의 MST 포함 여부
##key[v]는 MST에 속한 정점과 v가 연결될 때 최소 가중치
##최초 key는 가능한 가중치 최댓값 이상으로 초기화해놓는다
key = [10000]*(v+1)
##최초 임의로 고른 시작 정점의 key는 0
key[r] = 0
for _ in range(v): ##v+1개의 정점 중에서 시작 정점 r을 제외한 v개를 선택한다
##MST에 포함되지 않은 정점 (MST[u] == 0)중에서 가중치 key가 최소인 u를 찾는 작업
u = 0
min_w = 10000
for i in range(v+1):
##MST에 포함되지 않고, 최소의 가중치를 가지는 node를 찾는다.
if MST[i] == 0 and key[i] < min_w:
u = i
min_w = key[i]
MST[u] = 1 ##최솟값을 가지는 가중치를 가진 정점 u를 MST에 포함
##최초 여기까지는 u = 0일거임.. 나머지는 전부 key 가중치가 10000으로 최대니까
##MST에 포함된 u에 인접한 w에 대하여.. MST에 포함되지 않은 정점을 찾는 과정
for w in range(v+1):
##인접행렬 값이 0보다 크면 인접해있다는 의미
if MST[w] == 0 and adjM[u][w] > 0: ##w가 MST에 포함되지 않았고, w가 u에 인접해있으면..
key[w] = min(key[w], adjM[u][w]) ##w의 key와 u-w사이 가중치중 최솟값으로 key[w]를 갱신
##최초에 u=0이고, u=0과 인접한 모든 w에 대해 최소 비용을 가지는 key[w]를 찾게 될거
##다음 반복으로 가면 u = w가 될거고.. 계속 반복..
return sum(key) ##최소 가중치들의 합이 최소 신장 트리의 비용
##노드의 개수와 간선의 개수
v,e = map(int,input().split())
#인접행렬
adjM = [[0]*(v+1) for _ in range(v+1)]
for _ in range(e):
a,b,w = map(int,input().split())
adjM[a][b] = w
adjM[b][a] = w ##최소 신장 트리는 무방향 그래프를 가정
prim(0,v)
"""
6 11
0 1 32
0 2 31
0 5 60
0 6 51
1 2 21
2 4 46
2 6 25
3 4 34
3 5 18
4 5 40
4 6 51
175
"""
5. 변형된 프림 알고리즘 구현 예시
위 알고리즘은 선택한 정점에 대해서만 인접한 정점과 최소 비용을 찾아나가는데..
실제로 예시 설명할때는 MST에 포함된 모든 정점과 인접한 정점사이 최소 비용을 찾아나갔잖아
0을 선택하면 0과 인접한 비용중 최소가 2였고..
다음에 0,2와 인접한 비용중 최소가 1이였고..
다음에 0,1,2와 인접한 비용중 최소가 6이였고...
다음에 0,1,2,6과 인접한 비용중 최소가 4였고..
다음에 0,1,2,4,6과 인접한 비용중 최소가 3이였고..
다음에 0,1,2,3,4,6과 인접한 비용중 최소는 5였다
이 알고리즘은 어느 상황에서도.. 매우 느리다..
##변형된 프림 알고리즘
def prim(r,v): ##임의로 고른 시작 정점 r, 마지막 정점 v
MST = [0]*(v+1)
MST[r] = 1 ##시작 정점은 이미 MST에 포함
s = 0 ##최소 비용 신장트리의 가중치 합
for _ in range(v): ##선택된 r을 뺀 나머지 v개의 정점 선택하기
##인접한 정점 중에서 최소 비용을 가지는 간선을 연결시키는 정점 선택
u = 0
min_w = 10000
for i in range(v+1):
if MST[i] == 1: ##MST에 포함된 정점 중에서..
for j in range(v+1):
##MST에 포함되지 않았고, i와 인접하면서.. 최소 가중치인 j를 찾는다
if adjM[i][j] > 0 and MST[j] == 0 and min_w > adjM[i][j]:
u = j
min_w = adjM[i][j]
s += min_w
MST[u] = 1 ##그렇게 선택된 정점 u를 MST에 추가
return s
v,e = map(int,input().split())
adjM = [[0]*(v+1) for _ in range(v+1)]
for _ in range(e):
a,b,w = map(int,input().split())
adjM[a][b] = w
adjM[b][a] = w
prim(0,v)
"""
6 11
0 1 32
0 2 31
0 5 60
0 6 51
1 2 21
2 4 46
2 6 25
3 4 34
3 5 18
4 5 40
4 6 51
175
"""
6. 최적화된 프림 알고리즘 구현 예시
우선순위 큐를 이용하면 $O((V+E)logV)$의 시간 복잡도를 가지게 할 수 있다고 한다.
인접한 간선중에 가중치가 적은 순서대로 우선순위 큐에 넣어놓고 필요할때 pop하면.. 최솟값을 찾는 과정이 생략될거
아무튼 핵심은?
임의의 시작 정점을 고른다
시작 정점에 인접한 정점들의 우선순위 큐를 생성한다
시작 정점을 MST에 포함시킨다
우선순위 큐가 빌때까지 반복문을 돈다
가중치가 가장 적은 인접 정점을 뽑아내고, 해당 정점이 MST에 포함되어있는지 검사
MST에 포함된 정점이 아니라면, 포함 시키고 이 정점과 인접한 정점들을 우선순위 큐에 넣는다
어느 상황에서도 안정적으로 속도를 보장함
특히 인접행렬 사용 못하면.. 이 친구를 선택해야함
##최적화된 프림 알고리즘
import heapq
def prim(r,v,adjL): ##임의로 고른 시작 정점, 마지막 정점
MST = [0]*(v+1) ##MST에 포함된 정점 여부 확인
MST[r] = 1 ##최초 시작점은 MST에 포함
##시작 점과 인접한 정점의 정보를 찾는다.
adj_node = adjL[r]
heapq.heapify(adj_node) ##우선순위 큐 생성
s = 0 #최소 신장 트리의 비용
while adj_node: ##우선 순위 큐가 빌때까지..
w,a = heapq.heappop(adj_node) ##가중치가 가장 작은 간선을 추출
if MST[a] == 0: ##MST에 포함되지 않았다면..
MST[a] = 1 ##MST에 포함시키고
s += w ##가중치를 더해준다.
for edge in adjL[a]: ##MST에 새로 포함된, a와 인접한 정점에 대하여..
if MST[edge[1]] == 0: ##아직 MST에 포함되지 않은 정점이라면..
heapq.heappush(adj_node,edge) ##우선순위 큐에 모두 넣어준다
return s
##노드의 수, 간선의 수
v,e = map(int,input().split())
##인접리스트 방식으로 그래프를 표현
adjL = [[] for _ in range(v+1)]
##간선 정보 넣기
for _ in range(e):
a,b,w = map(int,input().split())
##가중치가 적은 순서대로 정렬해야하므로, 가중치를 먼저 넣자
adjL[a].append((w,b))
adjL[b].append((w,a))
prim(0,v,adjL)
"""
6 11
0 1 32
0 2 31
0 5 60
0 6 51
1 2 21
2 4 46
2 6 25
3 4 34
3 5 18
4 5 40
4 6 51
175
"""
7. 기타
문제 몇문제 풀어봤는데
위 3가지 알고리즘중에 우선순위 큐 쓴다고 항상 더 빠르진 않더라
이게 우선순위 큐에 push하면서 계속 정렬해야하니까 시간이 더 느려질수도 있나봐??
아니면 O((V+E)logV)에서 최악으로 간선의 개수가 너무 많으면 상당히 느려지나봄..?
일단 내가 내린 결론은
메모리 제한을 봤을때 (v+1)*(v+1)의 인접행렬을 사용가능하면 기본형이 훨씬 빠르다
그러니까 v가 너무 크면 우선순위 큐를 이용한 프림 알고리즘을 무조건 써야함
변형된 알고리즘은 너무 느리니까 사용하지 않는게 나은것 같다
참조
[알고리즘] 프림 알고리즘(Prim Algorithm) (tistory.com)
[알고리즘] 프림 알고리즘(Prim Algorithm)
프림 알고리즘(Prim Algorithm) 오늘은 프림 알고리즘에 대해 공부했습니다. 프림 알고리즘은 주어진 무방향 그래프내에서 MST를 찾는 알고리즘입니다. 프림 알고리즘은 다익스트라 알고리즘과
deep-learning-study.tistory.com
프림 알고리즘(Prim's Algorithm) :: 스터디룸 (tistory.com)
프림 알고리즘(Prim's Algorithm)
읽기 전 불필요한 코드나 잘못 작성된 내용에 대한 지적은 언제나 환영합니다. 개인적으로 사용해보면서 배운 점을 정리한 글입니다. 프림 알고리즘(Prim's Algorithm)이란? 최소 신장 트리(Minimum Span
8iggy.tistory.com
'알고리즘 > 최소 스패닝 트리' 카테고리의 다른 글
| 최소 스패닝 트리를 이용해서 그래프를 두 집합으로 분리하기(크루스칼 알고리즘 미세팁) (0) | 2023.07.27 |
|---|---|
| 최대 비용을 가지는 신장 트리를 만드는 방법? (0) | 2023.04.20 |
| 최소 신장 트리를 구하는 프림 알고리즘, 크루스칼 알고리즘 재활하기1 (0) | 2023.04.18 |
| 최소 신장 트리를 찾는 크루스칼 알고리즘 파헤치기 (0) | 2022.10.03 |