

1. motivation
R-CNN family는 Region proposal을 하고 각각 detection하는 2단계 구조(two-stage detector)
그러나 때로는 정확도를 조금 포기하더라도 real time detection 개념으로 매우 빠르게 실시간에 detection하는 것이 필요할 때가 있다
ROI pooling을 제거하여 single stage로 detection이 가능한 모형들이 등장했다

2. YOLO
먼저 input 이미지를 S*S grid로 나눈다

각각의 grid cell에 대해 B개의 bounding box를 고려한다
각 box에 대한 중앙점의 좌표와 너비,높이 (x,y,w,h) 4개의 위치 모수 그리고 object를 포함하는지 안하는지 confidence score를 계산
여기서 (x,y)는 bounding box 중앙점의 grid cell내 상대적인 위치로 0~1까지 값을 가지며 둘의 중앙점이 동일하면 x=0.5,y=0.5
w,h도 이미지 전체의 너비와 높이에 대한 bounding box의 상대적인 크기로 0~1값을 가진다
confidence score는 실제 object의 bounding box와 예측한 bounding box의 IoU와 예측 bounding box내에 object가 존재할 확률의 곱으로 계산

다음으로 각각의 grid cell에 대한 conditional class probability를 계산한다
cell내에 object가 존재한다고 가정할 때 그 object가 어떤 class에 속할지 조건부확률을 구한 것이다.
하나의 cell이 B개의 bounding box를 예측하는데 이거와 무관하게 하나의 cell 내에 존재하는 하나의 object에 대해서 probability를 구하는 것

최종적으로 conditional class probability와 confidence score를 곱한 class specific confidence score를 구한다
이 값은 box내에 그 class object가 등장할 확률과 box가 그 object에 얼마나 잘 들어맞는지를 나타내는 값

3. training sample
B개의 box proposal을 예측하니 하나의 object에 여러개의 box proposal이 제시될 수 있다
ground truth와 IoU가 가장 높은 box를 positive sample로 사용한다고 한다(하나만 사용하는 것 같음)
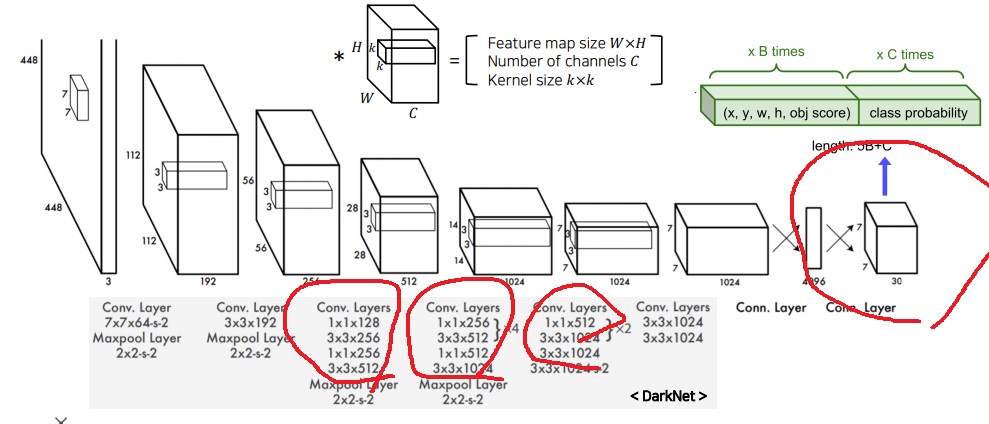
4. 전체 구조
GoogleNet에서 아이디어를 받았는데 inception구조 대신에 1*1 convolution layer와 3*3 convolution layer를 반복적으로 사용했다
마지막이 7*7*30 tensor인 이유는 논문의 세팅이 S=7,B=2, C=20이어서 그렇다고 한다
5. 성능
당시 real time detection 알고리즘중 압도적인 성능을 보임
two stage detection 알고리즘인 Faster R-CNN보다 성능은 조금 떨어졌다

FPS는 속도, mAP는 성능
YOLO VGG-16에서 VGG-16은 backbone network
'딥러닝 > Computer Vision' 카테고리의 다른 글
| instance segmentation과 mask R-CNN알아보기 (0) | 2022.10.21 |
|---|---|
| 불균형 데이터에 효과적인 Focal loss (0) | 2022.05.16 |
| R-CNN 계열의 network 원리 요약 (0) | 2022.05.10 |
| R-CNN에서 가장 발전된 Faster R-CNN에 대하여 (0) | 2022.05.05 |
| object detection을 위한 R-CNN과 Fast R-CNN의 원리 (0) | 2022.05.05 |