

1. how much
quantization을 얼마나 했느냐에 따라
32bit가 full precision이라면 절반씩 줄여나가는 16bit quantization, 8bit, 4bit, 2bit, 1bit quantization

mixed precision으로 quantization하는 기법은 hardware-oriented compression(혹은 hardware-aware compression)에 사용된다고 함
무슨 말이냐면 hardware 친화적인 compression, 사용하는 hardware에 맞춘 compression
구체적으로 아주 미세한 layer 단위에서 어떤 layer는 3bit, 어떤 layer는 5bit quantization을 하는 등 layer 단위로 섞어서 다른 quantization을 적용하는 기법
2. how to
quantization을 어떻게 하느냐에 따라
static quantization은 post training quantization이라고도 부르는데 이름에 따라 training을 다 하고 나서
weight와 activation을 정해진 bit수에 따라 quantization을 함
dynamic quantization은 weight는 일단 quantization을 하는데
activation의 경우는 inference time에만 잠깐 quantization을 하여 속도를 높이면서 결과를 내놓고
다시 training time에는 원래대로 activation을 사용하는 방법

static quantization과 dynamic quantization은 hardware-aware quantization
3. when to
post-training quantization은 training 후에 quantization을 수행
위에서 말한 static quantization이랑 똑같음
quantization-aware training은 training 과정 중에 quantization을 수행함
구체적으로 training과정에 fake node를 가져다두고 나중에 이 값이 quantize되면 어떤 값을 줄지 simulation을 함
원래 quantization전에 training중 loss가 있고 quantization한다면 생기는 loss는 조금 차이가 있는데
이 quantize되면 loss가 어떻게 변할 것인지 인지하여 training하는 방법이 quantization-aware training이다.

4. what to
위에서 보면 quantization은 weight와 activation에 quantization을 수행할 수 있음
5. dynamic quantization
weight를 먼저 quantization하고 activation은 inference time에 dynamic하게 quantization하는 방법
구체적으로 inference에는 activation을 quantization하여 결과를 빠르게 내놓은 뒤에 다시 원래대로 되돌려서 training을 수행하는 방법
quantization 정도도 dynamic하게 결정을 하나봐
runtime동안에 관측된 데이터의 범위에 기반한 activation quantization의 scale factor를 결정해야함
model의 execution time(inference time인가?)에 matrix multiplication을 수행하는 시간보다
메모리로부터 weight를 load하는 시간에 완전히 영향받을때(dominated by) 사용된다
LSTM이나 Transformer을 small batch로 사용할때 효과적이라고 함
6. static quantization
앞에서 말한 것처럼 training후에 weight와 activation을 quantization하는 것
post training quantization이라고도 부름
일반적으로 모델이 사용하는 양보다 메모리 양이나 계산비용을 절약하고 싶을 때 사용함
“it requires calibration with a representative dataset to determine optimal quantization parameters for activations.”
이런 말이 있는데 calibration이 뭔가 찾아봤더니 “모형의 출력값이 실제 결과를 반영할 수 있는 정도”라고 함
Calibration is comparison of the actual output and the expected output given by a system 혹은 뭐 이런 말도 있는데 보면 실제 결과와 예측 결과를 비교하는 것 정도로 이해하면 될 것 같음
그러면 저 말을 해석해보면 “activation에 대한 최적의 quantization parameter를 결정지을 수 있는 대표적인 dataset에 대한 calibration이 있어야 가능하다”
quantization을 하고 나서 모델의 inference 결과가 quantization 하기 전 inference 결과를 어느정도 반영할 수 있어야 한다 이런 느낌 같음 그래야 quantization이 의미 있지
7. quantization aware training
During training, all calculations are done in floating point, with fake_quant modules modeling the effects of quantization by clamping and rounding to simulate the effects of INT8.
training 중에 quantization을 하는데 모든 계산은 floating point로 함
근데 fake module로 int8? quantization을 하면 loss변화가 어떨지 그 효과를 simulation한다고 함
이 simulation과정이 quantization을 modeling한다고 말함
simulation 결과(modeling한 quantization 결과)를 변환(conversion)하면 weight와 activation이 quantization되나봄?
일반적으로 static quantization에 비해서 혹은 다른 quantization에 비해 높은 정확도를 낸다고함
8. 그림으로 알아보는 quantization

일반적인 초기 모델 M0을 training하면 M1으로 수렴하고 true model과 상당히 가깝다
true model과 가까울수록 정확도가 높은 것임
training을 하고나서 quantization을 수행하면 post-training quantization이 되는 것이고 M2가 된다
보면 M2와 true model이 거리가 멀어지면서 정확도가 떨어졌는데
이렇게라도 quantization하는 이유는 inference time에서 속도가 M1보다 빨라지기 때문임
두번째로 inference time에만 quantization을 수행하여 dynamic quantization이 되면서 model M4가 된다
weight는 quantization하고 activation만 inference때 잠깐 quantization되어 결과를 내놓고 다시 원래대로 되돌려 training하는 방법
당연하지만 true model과 멀어지면서 정확도가 떨어지는데 inference time에 속도가 빨라지는 방법
quantization aware training은 초기 모델 M0을 training 시킬 때 training한 다음에 quantization을 시킬 것이라는
그 결과를 simulation하면서 training을 수행함
실제로 M1쪽으로 training된 다음에 quantization modeling을 반영하여 quantization을 수행하니 그나마 정확도가 나머지 quantization에 비해 제일 높음

quantization은 그 기법내에서도 여러가지 방법이 있다
모든 hardware가 그러한 기법을 지원하지는 않는다
심지어 모든 library 예를 들어 tensorflow나 pytorch가 각각 모든 기법을 지원해주는 것도 아니다
그래서 내가 어떤 hardware를 쓰고 있는지 어떤 library를 쓰고 있는지 고려하면서 적절한 기법을 선택해야한다.

9. quantization range
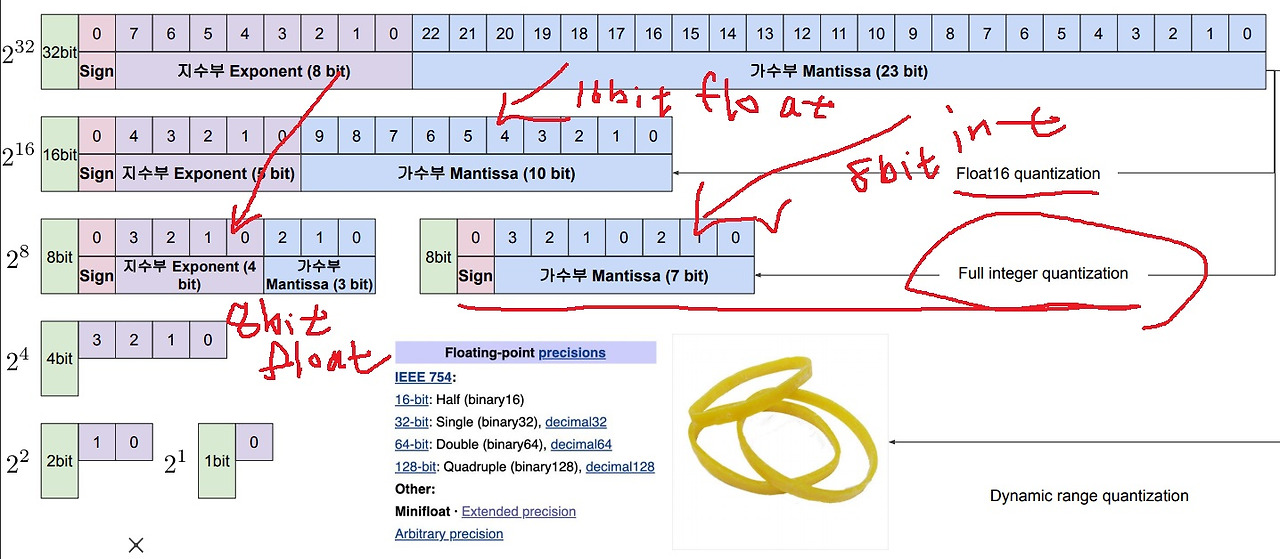
32bit float에서 full integer quantization으로 int8 quantization을 가장 많이 사용함
quantization이 float에서 int로만 quantization하는 것만 생각할 수 있는데 float에서 float로도 quantization하는 것도 있음
32bit float에서 half precision인 16bit float로 변환하는 것도 일종의 quantization임
dynamic quantization은 위 그림에서도 볼 수 있듯이? inference time에 activation에 대한 quantization scale이 dynamic하게 변함
변하는 정도는 위에서 설명했듯이 관측된 data range에 따라 다르다고
10. post training quantization guide
quantization을 해야하나 말아야하나? 안해도 된다면 TFLite로 변환하여 모델을 돌리고
해야한다면 float16 half precision을 지원하는 GPU를 쓸 필요가 있느냐 없느냐?
필요없다면 MCU나 TPU같은 특수한 장비를 사용한 integer quantization을 수행?

representative dataset이 뭔가 찾아봤는데
- A representative set is a special subset of the original dataset, which has three main characteristics: It is significantly smaller in size compared to the original dataset. It captures the most information from the original dataset compared to other subsets of the same size. It has low redundancy among the representatives it contains.
- A representative set consists of selective samples from the original dataset. It captures significant information in the original dataset more efficiently than any random samples can.
original set의 특별한 부분집합인데 그 크기는 상당히 작고 그럼에도 불구하고 original set의 대부분의 정보를 담고 있음
아무튼 그 외에 int8 연산이 필요하느냐 필요없느냐에 따라 다르고
마지막에 보면 conversion fails if the model has unsupported operation이 있는데
quantization되더라도 지원하는 hardware가 없으면 안돌아가는 경우가 생각보다 많음
11. post training quantization vs. quantization aware training
앞의 내용이랑 비슷한데 post training quantization은 parameter size가 큰 모형에 적합하고
quantization aware training은 정확도 하락을 최소화시킬 수 있다는 점

아래 (b)가 simulation하는 그림이라는데 마지막에 act quant한다는 것이 위에서 말했듯이 simulation하고 나서 quant적용하여 output낸다는 의미?
pretraining때 post training quantization을 하고나서 fine tuning때 quantization aware training을 하기도하고
위에서 보면 quantization aware training dataset에 fine tuning dataset requirement가 있어야한다고 했는데 이 말인듯?
post training quantization만 하기도하고
quantization aware training만 하기도하고


12. quantization aware training 또 다른 설명?
forward pass에서 training과 inference 모두 precision을 일치시키는 것을 목표로 한다
training time에 inference의 quantization 효과가 modeling됨
Operator fusion at inference time are accurately modeled at training time.
이런 말이 있는데 inference time에서 operator fusion이 training time에 정확하게 모델링된다는 뜻이겠지?
operator fusion이 뭔지 찾아보니까 어떤 연산과 다른 연산을 합치는거
예를 들어 머신러닝 같은 경우에는 convolution 연산(output of each layer)을 한 뒤에 activation 연산(nonlinearity)을 수행하는데 이 두 연산을 한번에 하는거
quantization error가 forward, backward pass에서 quantization 효과를 simulation하는 fake quantization node를 사용하여 모델링됨
forward와 backward 모두에서 quantization 효과를 simulation함
Note that during back propagation, the parameters are updated at high precision as this is needed to ensure sufficient precision in accumulating tiny adjustments to the parameters.
이런 말이 있는데 backward 계산에는 quantization 계산을 하고 parameter update에는 조금 더 high precision으로 update하는 것 같음. 충분한 정확도를 보장하기 위해서겠지??
13. recommend workflow
NLP task에서 quantization을 어떻게 하면 좋을지 하나의 가이드라인을 제시한 논문이다
이런 논문은 그냥 제안일뿐 믿으면 무조건 손해다. 뭐든 직접해봐야 아는법
post training quantization을 수행하고 성능이 생각한 것 보다 별로면 partial quantization을 수행하고 아니다 싶으면 quantization aware training을 수행해라라는게 요약
partial quantization은 mixed precision으로 다양한 precision을 활용한 quantization을 섞어서 한다는 의미겠지

weight같은 경우는 symmetric range quantization을 하고 column별이나 channel별로 quantization을 해라
activation은 tensor별로 scale quantization을 해라 이게 symmetric range quantization아닌가?
pretrain network를 post training quantization - partial quantization - quantization aware training 순으로 해봐라
post training quantization은 convolution이나 linear layer같은 intensive layer를 quantization을 하고 activation을 잘 해보라는 얘기인가???
calibration이 원하는 만큼 안나오면 partial quantization을 수행해라
partial quantization은 quantization에 민감한 layer는 floating으로 놔두고 quantization을 수행하는 mixed quantization을 수행해라
성능이 안나오면 quantization aware training을 해라
앞에서 최고로 성능이 좋았던 모델부터 시작해서 fine tune을 quantization aware training으로 해라
initial learning rate의 1%인 annealing learning rate schedule
original data의 10%만 fine tuning해라 라는 식으로 구체적인 가이드라인을 제시함
'딥러닝 > light weight modeling' 카테고리의 다른 글
| DoReFa-Net과 binarized neural network (0) | 2025.04.13 |
|---|---|
| hardware optimization이 일어나는 원리 locality of reference (0) | 2024.11.26 |
| lottery ticket을 찾는 방법들로 제안된 방법들 살펴보기 (0) | 2024.11.25 |
| neural network에서의 low rank approximation은 무엇이 있는가 (0) | 2024.11.20 |
| 가장 좋은 augmentation을 찾기 위한 시도들 - AutoML, Rand augmentation (0) | 2024.10.01 |