

https://heekangpark.github.io/ml/shorts/padded-sequence-vs-packed-sequence
Padded Sequence vs. Packed Sequence | Reinventing the Wheel
문제상황 자연어와 같은 sequence 데이터들을 다루다 보면 짜증나는 요소가 하나 있는데, 바로 그 길이가 일정하지 않다는 것이다. 이미지 데이터의 경우 crop이나 resize 등으로 가로 세로 크기를 맞
heekangpark.github.io
자연어같은 sequence 데이터는 input들의 길이가 다 다른 경우가 보통이기 때문에 이것을 어떻게 처리할 지 고민할 필요가 있다.
이미지는 crop이나 resize로 이미지 크기를 전부 맞추고 진행하면, batch로 만들기 쉽다.
하지만 sequence 데이터는 길이가 다양하기 떄문에 하나의 batch로 묶어지지 않는다
https://deepdata.tistory.com/1144
NLP text data 전처리에서 tokenizing할 때 padding이 필요한 이유
text 데이터는 보통 길이가 서로 달라서 전처리할때 padding을 해서 길이를 맞춰준다고 보통 그러는데 왜 해야할까? 보통 batch형태로 데이터를 만들어서 모델을 학습시키는데, 길이가 서로 다르면 b
deepdata.tistory.com
그렇다고 batch 연산을 포기하고 하나씩 하나씩 모델에 넣어 연산할 수도 있지만, 그러기에는 속도가 너무 느리다.
길이가 다른 sequence 데이터를 묶어 batch 연산을 수행하게 해주는 전략이 padding과 packing이 있다.
모델에 따라 적절한 방법이 있다.
1. padding sequence
hello world, midnight, calculation, path, short circuit를 input으로 받아들여 embedding을 했는데
텐서 길이가 전부 다른 것을 확인할 수 있다.

sequence input중 가장 긴 길이의 input에 길이를 맞추기 위해 나머지 input들의 빈 부분에 padding을 하는 방법
padding은 아무런 의미 없는 값으로, 대표적으로 0을 넣는다
모델 입장에서는 이 padding된 부분을 무시하고 연산을 수행하면 된다.
torch.nn.utils.rnn.pad_sequence 함수로 구현가능하다
https://pytorch.org/docs/stable/generated/torch.nn.utils.rnn.pad_sequence.html
torch.nn.utils.rnn.pad_sequence — PyTorch 2.2 documentation
Shortcuts
pytorch.org
sequences는 tokenize된 sequence들의 list를 준다. 위 코드에서 X
batch_first는 padding후에 batch의 차원을 어디로 설정할지 선택한다.
batch_first가 False이면 (max_seq_length, batch_size, ... )
기본값이 False
batch_first가 True이면 (batch_size, max_seq_length, ... )
보통 huggingface의 transformer를 사용하는데, batch 차원이 첫번째 차원이기 때문에
huggingface 모델을 쓴다면, 웬만하면 batch_first = True로 하는게 좋다.
padding_value는 padding에 사용할 값

제일 긴 길이의 input에 맞춰 나머지는 전부 0으로 채워넣어준 모습
이렇게 하면 서로 크기가 달랐던 5개의 tensor가 (5,13)의 하나의 tensor로 만들어진다.

padding은 transformer 기반의 모델에 사용하는 것이 좋다.
huggingface의 transformers 라이브러리의 경우 대부분의 모델이 padding을 사용한 batch 입력을 받을 수 있다.
transformers에서는 일반적으로 해당 모델에 대응하는 tokenizer를 이용해, input을 tokenizing하는데,
padding = True, return_tensors = 'pt' 등의 옵션을 주어, 길이가 가장 긴 sequence에 맞춰 padding을 수행하고,
하나의 batch tensor를 반환한다.
그리고 tokenizer가 attention mask도 반환하는데, attention 연산이 수행되어야 할 부분은 1, 아닌 부분은 0으로 체크된다.
padding의 경우 attention 연산이 수행되면 안되니까 0으로 되어있는데, 이 attention mask도 같이 모델에 넣어주어,
모델이 padding된 부분에 대해서는 연산을 수행하지 않도록 한다.
2. packing sequence
padding의 문제점은 굳이 계산하지 않아도 되는 0으로 채워진 부분을 계산해야하는 문제점이 생긴다
transformer 기반의 모델의 경우, input을 왼쪽 token부터 오른쪽 token까지 순차적으로 처리할 필요 없이,
한번에 처리할 수 있지만
RNN 기반의 모델의 경우 왼쪽 token부터 오른쪽 token으로 time step에 맞춰 순차적으로 입력이 진행되어야 한다.
따라서 RNN 기반의 모델에서 batch연산을 하기 위해 모든 input에서 첫번째 token을 모아 batch로 만들고,
두번째 token을 모아 batch로 만들고, .....이런 식으로 세로 방향으로 sequence들을 읽어낸다면?

한 문장을 처리할 때, 이렇게 가로방향으로
John > lives > in > a > beautiful > mansion > with > a > swimming > pool. 읽고 나서,
다시 두번째 문장
John > is > a > good > swimmer.을 읽고...
이렇게 하면 batch 단위로 처리할 수 없어서
John lives in a
John >>> is >>>>> a >>>>>>>>>> good >>>>>>>
John loves to swim.
이런식으로 세로방향으로 동일한 위치에 있는 것을 하나로 묶어서 처리하자.
[John, John, John, lives, is, loves, in, a, to, a, good, swim. , beautiful, swimmer, mansion, with, a, swimming, pool]
이렇게만 하면 각 batch마다 어떤 token들이 묶이는지 알 수 없어서 batch size도 알고 있어야한다
각 step마다 몇개의 token들이 묶이는지
[3,3,3,3,2,1,1,1,1,1]
그러면 모델은 step마다 batch size를 보고 packing된 sequence에서 batch size개만큼 데이터를 묶어서 읽을 수 있게 된다.
pytorch에서는 이것을 효율적으로 구현하기 위해 먼저 input들을 길이의 내림차순으로 정렬해야한다.
당연하지만, input들을 길이 내림차순으로 정렬하면 각 input에 대응하는 label도 같은 순서로 맞춰줘야한다.
torch.nn.utils.rnn.pack_sequence로 구현할 수 있다
https://pytorch.org/docs/stable/generated/torch.nn.utils.rnn.pack_sequence.html
torch.nn.utils.rnn.pack_sequence — PyTorch 2.2 documentation
Shortcuts
pytorch.org
sequences는 tokenize된 (길이의 내림차순으로 정렬되어 있는)sequence들의 list
enforce_sorted는 sequence들의 리스트가 길이 순서로 내림차순 정렬되어 있는지 확인
기본값은 True이고 True인데 내림차순 정렬되어 있지 않으면 에러가 난다


padding의 경우, padding하고 나서, 세로 방향으로 읽어 packing하고 batch로 만들 수 있지만
padding된 부분에 대해서도 RNN이 연산을 수행해버리기 때문에 효율적이지 않다.
packing을 통해 실제 input에 대해서만 연산을 수행할 수 있어 효율적이다.
transformer 모델의 경우에도 packing을 사용할 수 있지만, 메리트가 별로 없다.
입력 순서가 중요하지 않기 때문에 오히려 구현이 복잡해질 뿐 padding을 사용하는 것이 낫다.
3. pack padded sequence
여기 부분이 무슨말인지 모르겠었는데... 위 내용을 읽어보니 이해가 간다
-------------------------------------------------------------------------------------------------------------------------------------------------
padding은 sequence의 최대길이에 sequence 데이터들을 맞추고자 하기 위해서 사용한다.
pad는 사실 길이를 맞추기위해 넣은 더미데이터인데 불필요하게 계산을 한다는 점이 문제다.
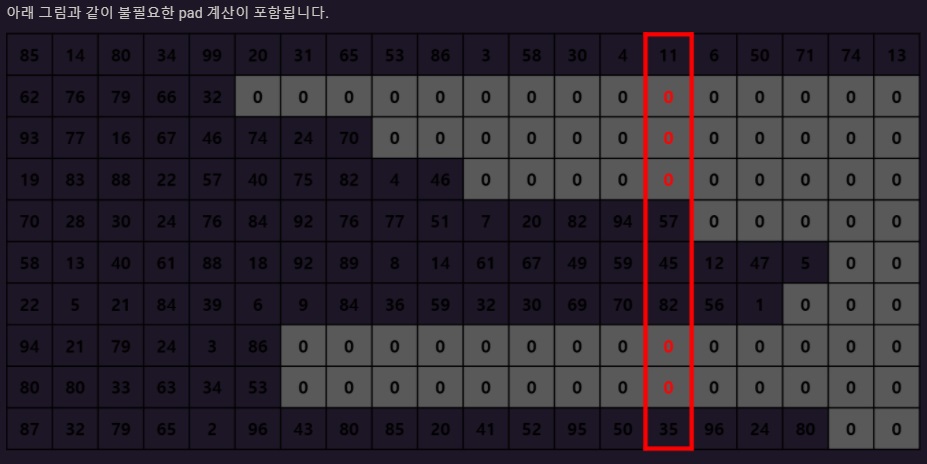
그래서 이 계산을 줄이고자 sequence를 길이 내림차순 정렬하여 packed sequence 형태로 만든다.

그러면 이제 위에서부터 아래로 계산만 하면 되니까 pad를 계산할 필요가 없어진다.
실제 RNN에 이런 방식으로 계산하겠다고 알려주기위해 packed sequence object로 처리해야한다.
------------------------------------------------------------------------------------------------------------------------------------------------------
pack_sequence()함수는 내부적으로 pad_sequence()와 pack_padded_sequence()를 순차적으로 호출하도록 구현되어 있다고 한다.
torch.nn.utils.rnn.pack_padded_sequence로 구현할 수 있다
pack_padded_sequence()는 padding을 packing으로 변환해주는 함수

옵션은 위에서 본거랑 동일하다
https://pytorch.org/docs/stable/generated/torch.nn.utils.rnn.pack_padded_sequence.html
torch.nn.utils.rnn.pack_padded_sequence — PyTorch 2.2 documentation
Shortcuts
pytorch.org

그러나 이제 이렇게 RNN에 넣으면 output이 원하는 형태로 나오진 않는다. 이럴때 다시 unpack해줘야한다.
torch.nn.utils.rnn.pad_packed_sequence로 구현할 수 있다
packing된 sequence를 padding으로 바꿔주는 함수이다.
https://pytorch.org/docs/stable/generated/torch.nn.utils.rnn.pad_packed_sequence.html
torch.nn.utils.rnn.pad_packed_sequence — PyTorch 2.2 documentation
Shortcuts
pytorch.org


'프로그래밍 > Pytorch' 카테고리의 다른 글
| Unexpected key(s) in state_dict: "model.electra.embeddings.position_ids". 에러 해결하기 (0) | 2024.10.30 |
|---|---|
| Pytorch model forward에서 에러나는 경우 대처하기(input output model shape print해보기) (0) | 2024.08.25 |
| Pytorch에서 learning rate scheduler 사용하는 방법 알기 (0) | 2024.04.17 |
| torch.where()로 tensor내 특정 원소의 위치를 찾기 (0) | 2024.04.14 |
| Pytorch의 computational graph와 backward()에 대해 이해하기 (0) | 2024.04.13 |