

1. 세미콜론
모든 수행 문장이 끝날 때 최종적으로 마지막에 세미콜론 ; 으로 끝냄
2. 특정 칼럼 조회
2-1) 기본형식
select (칼럼) from (테이블명);
2-2) 모든 칼럼 조회
select * from (테이블명);
3. 조건 지정
3-1) where문 사용
select * from (테이블명) where (조건):
> 테이블에 존재하는 모든 칼럼을 조회하는데 조건에 맞는 행만을 조회함
> where emp.ename="kim"; 처럼 (테이블명).(칼럼명)으로 칼럼을 지정할 수 있음
3-2) 연산자
일반적인 프로그래밍 언어와 비슷한 연산자들을 지원함
where A = 1000;
where A >= 1000;
where A <= 1000;
where A != 1000;
where A >= 1000 AND B <= 2000;
SQL에서 사용하는 특별한 연산자들도 있다
where A between 1000 and 2000;
> A가 1000이상 2000이하인 행을 조회
where A IS NULL;
> A가 NULL인 행을 조회
where A IS NOT NULL;
> A가 NULL이 아닌 행을 조회
4. 별칭
칼럼명을 원하는 별칭을 지정하여 조회할 수 있음
4-1) as 사용
select A as "이름" B as "연봉" from (테이블명);
>테이블에서 A,B를 조회하는데 A를 "이름"으로 B를 "연봉"으로 출력함
4-2) 테이블의 별칭
(테이블명) 바로 뒤에 별칭을 써서 다음 문장부터 별칭으로 사용할 수 있음
select A as "이름" B as "연봉" from (테이블명) a
where a.C=1000;
> 테이블에서 A,B를 조회하는데 테이블의 칼럼 중 C=1000을 만족하는 행만을 조회하고 A는 "이름", B는 "연봉"으로 출력을 함
5. 정렬
order by를 사용하여 정렬한 상태로 조회할 수 있음
select (칼럼) from (테이블)
order by (칼럼1) , (칼럼2) desc;
> 테이블에서 (칼럼)을 조회할건데 (칼럼1)로 오름차순 정렬하고 (칼럼1)이 서로 같으면 (칼럼2)로 내림차순 정렬함
> desc는 내림차순 정렬이고 asce는 오름차순 정렬인데 따로 지정하지 않으면 오름차순 정렬함
6. 통계량 계산
칼럼에 대한 통계량을 계산하고 싶은 경우 select 문에서 통계량 함수를 칼럼에 적용시켜서 조회할 수 있음
count() : 칼럼의 행 수를 조회
> count(*) null을 포함한 모든 행 수를 계산함
> count(칼럼명) null을 제외하고 행 수를 계산함
sum() : 칼럼의 총 합을 계산
avg() : 칼럼의 평균을 계산
max(), min() : 최댓값과 최솟값
stddev() : 칼럼의 표준편차를 계산
varian() : 칼럼의 분산을 계산
abs() : 절댓값을 계산
mod(a,b) : a를 b로 나눈 나머지를 계산
ceil() : 해당 숫자보다 크거나 같은 최소의 정수를 계산
floor() : 해당 숫자보다 작거나 같은 최대의 정수를 계산
-------------------------------
ceil (천장)
숫자
floor (바닥)
-------------------------------
round(a,m) : a를 소수점 m자리로 반올림
trunc(a,m) : a를 소수점 m자리로 버림
select sum(B) from (테이블명)
where C between 1000 and 2000;
> 테이블에서 C가 1000이상 2000이하인 칼럼 B의 모든 값의 총합을 sum(B)로 나타내면서 조회함
7. 그룹화
group by를 사용하여 해당 칼럼의 값들로 그룹화 시킬 수 있음
select A,B from (테이블명)
group by C;
> 칼럼 C의 값들을 기준으로 그룹화 하여 A,B를 조회함
통계량 계산에 많이 이용함
예를 들어 테이블 EMP가 다음과 같다면
| A | B |
| 10 | 100 |
| 10 | 200 |
| 20 | 50 |
| 20 | 100 |
| 30 | 300 |
| 30 | 200 |
select A,sum(B) from EMP
group by A;
A를 기준으로 그룹화를 시킨 뒤 각 그룹별로 B의 총합을 조회해줌
A는 그룹이 10,20,30으로 나뉠 수 있고 각 그룹의 B값들의 합을 조회해줌
결과는 다음과 같을 것이다.
| A | sum(B) |
| 10 | 300 |
| 20 | 150 |
| 30 | 500 |
조건문을 사용하여 원하는 행만을 조회할 수 있는데 GROUP BY를 사용하면 WHERE이 아니라 HAVING을 사용함
select A,sum(B) from EMP
group by A
having sum(B) > 200;
위 테이블에서 sum(B)가 200보다 큰 행만을 조회함
결과는 다음과 같을 것이다.
| A | sum(B) |
| 10 | 300 |
| 30 | 500 |
8. IF문
DECODE( <조건> , <조건이 참> , <조건이 거짓> )
select DECODE(A,1000,'TRUE','FALSE') from emp;
> emp 테이블에서 A=1000이면 TRUE로 나타내고 1000이 아니면 FALSE로 나타내어 출력함
>칼럼 이름은 DECODE(A,1000,'TRUE','FALSE') 로 나옴
DECODE가 = 조건만 나타내니까 CASE문을 활용
CASE
when (조건1) then (조건1이 참이면)
when (조건2) then (조건1이 거짓이고 조건2가 참이면)
else (조건1이 거짓이고 조건2도 거짓이면)
end;
9 테이블 결합
9-1) inner join
두 테이블 table1, table2가 동일한 칼럼 C를 가지면 C를 기준으로 inner join하여 결합할 수 있다
select A,B from table1,table2
where table1.C=table2.C;
select A,B from table1 inner join table2
on table1.C=table2.C;
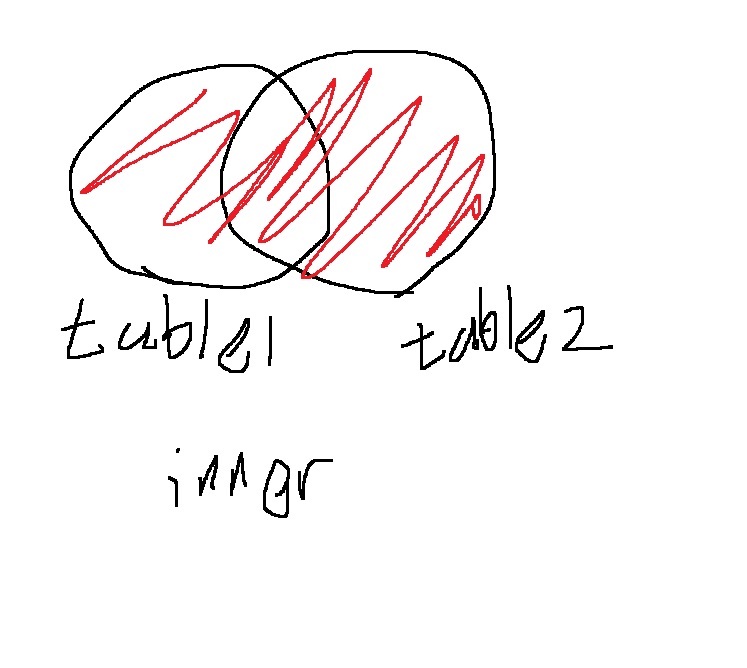
9-2) outer join
두 테이블 table1, table2가 동일한 칼럼 C를 가지면 C를 기준으로 outer join하여 결합할 수 있다
select A,B from table1 left outer join table2
on table1.C = table2.C;
select A,B from table1 right outer join table2
on table1.C = table2.C;

9-3) cross join
두 테이블을 그대로 붙여서 조회해줌
select * from A,B;
select * from A cross join B;
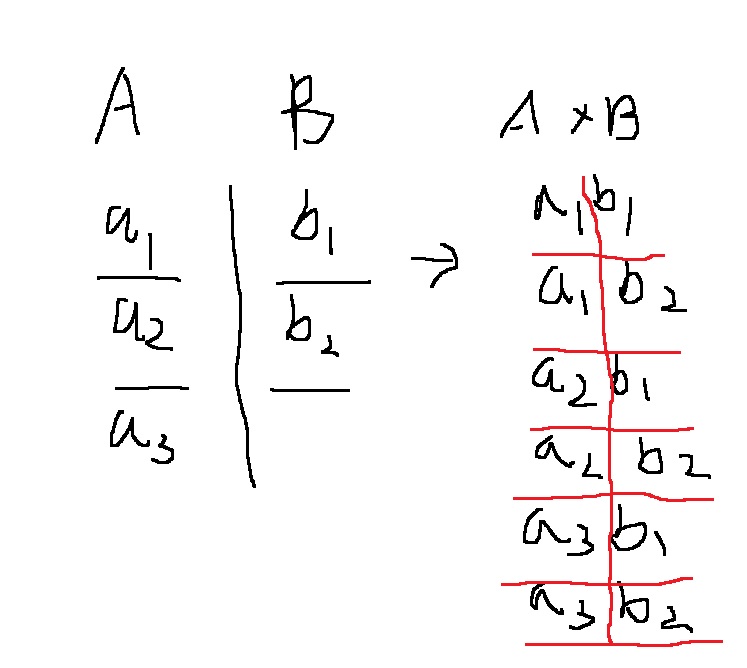
9-4) 집합 연산
UNION, UNION ALL, MINUS로 집합연산이 가능
UNION ALL은 중복을 제거하지 않고 모두 조회하고 UNION은 합집합을 구하면서 중복을 제거함
select A from table1
union
select A from table2;
select A from table1
union all
select A from table2;
select A from table1
minus
select A from table2;
10. 기타
10-1) 중복 제거
칼럼 앞에 distinct를 붙이면 중복을 제거하고 조회할 수 있음
select distinct A from table;
> table에서 A를 조회하는데 중복인 행은 제거함
10-2) IN
파이썬 프로그래밍에서 value가 리스트에 존재하는지 아닌지 검사할 때 쓰는 in이랑 비슷함
select * from table
where A in (x,y);
> A=x나 A=y인 행을 조회함
10-3) %
어떤 문자를 포함하는 모든 문자들을 조회함
예를 들어
where A LIKE 'test%';
A가 test로 시작하는 모든 문자와 같은지 조회함
where A LIKE '%est%';
A가 중간에 est가 들어가는 모든 문자와 같은지 조회함
where A LIKE '%3';
A가 끝이 3으로 끝나는 모든 문자와 같은지 조회함
_는 오직 하나의 문자만을 나타냄
where A LIKE 'test_';
A가 test로 시작하면서 뒤에 문자가 딱 하나만 더 있는 (예를 들어 testa, testb, testc, test3, test2, testd,....) 문자와 같은지 조회함
'프로그래밍 > SQL' 카테고리의 다른 글
| SQL 코딩테스트 복기 - 알파벳으로 시작하는 데이터 추출하는 방법(정규표현식) (1) | 2023.03.18 |
|---|---|
| MYSQL에서 스키마(데이터베이스) 생성하기 (0) | 2023.01.19 |
| SQL 코딩테스트 복기 -시간 데이터 다루기, 조건에 맞는 값 추출- (0) | 2023.01.08 |
| SQL 코딩테스트 복기 - 무조건 나오는 RANK함수 무조건 외우기 (0) | 2022.05.16 |
| SQL문 분석(코딩테스트 복기)하고 스킬 습득하기 (0) | 2022.04.22 |