

2024.03
1. 요약
이미지-텍스트 기반 모델(CLIP 등)의 대조적 사전 학습은 다양한 후속 작업에서 뛰어난 제로샷 성능과 향상된 강건성을 입증했습니다.
그러나 이러한 모델은 대규모 트랜스포머 기반 인코더를 사용하며, 이는 메모리와 지연 시간 측면에서 상당한 부담을 주어 모바일 디바이스에서의 배포에 어려움을 초래합니다.
본 연구에서는 MobileCLIP이라는 새로운 효율적인 이미지-텍스트 모델 군과 함께, 멀티모달 강화 학습(multi-modal reinforced training)이라는 새로운 효율적 학습 방법을 제안합니다.
제안된 학습 방법은 이미지 캡셔닝 모델과 강력한 CLIP 인코더 앙상블의 지식 전이를 활용하여 효율적인 모델의 정확성을 향상시킵니다.
우리의 접근 방식은 강화된 데이터셋(reinforced dataset)에 추가 지식을 저장하여 학습 시간 동안의 계산 오버헤드를 피합니다.
MobileCLIP은 여러 데이터셋에서 제로샷 분류와 검색 작업의 지연-정확성(tradeoff) 분야에서 새로운 최고 성능을 달성했습니다.
특히, MobileCLIP-S2 변형은 이전의 ViT-B/16 기반 CLIP 모델 대비 2.3배 빠르면서도 더 높은 정확성을 제공합니다.
또한, 우리의 멀티모달 강화 학습의 효과를 입증하기 위해 ViT-B/16 이미지 백본을 기반으로 한 CLIP 모델을 학습시켰으며, 이전 최고 모델 대비 38개 평가 벤치마크에서 평균 성능을 2.9% 향상시켰습니다.
더 나아가, 제안된 접근 방식은 비강화 CLIP 학습에 비해 학습 효율성이 10배에서 1000배까지 개선됨을 보여줍니다.
2. 소개
대규모 이미지-텍스트 기반 모델(예: CLIP [47])은 다양한 후속 작업 [30]에서 뛰어난 제로샷 성능과 향상된 강건성 [15]을 입증했습니다.
그러나 이러한 모델은 크기가 크고 지연 시간이 길어 모바일 디바이스에 배포하는 데 어려움이 있습니다.
우리의 목표는 모바일 디바이스에 적합한 새로운 이미지-텍스트 정렬 인코더 계열을 설계하는 것입니다.
이를 실현하기 위해 두 가지 주요 과제가 있습니다.
첫째, 실행 성능(예: 지연 시간)과 다양한 아키텍처의 정확성 간의 균형(tradeoff)을 고려해야 하며, 이를 위해 다양한 아키텍처 설계를 신속하고 철저히 분석할 수 있어야 합니다.
그러나 CLIP 모델의 대규모 학습은 계산 비용이 매우 높아 효율적인 아키텍처 설계를 신속히 개발하고 탐색하는 데 방해가 됩니다.
반면, 소규모에서 표준 멀티모달 대조 학습 [47]을 수행하면 낮은 정확도를 보여 아키텍처 설계 선택을 안내하는 데 유용한 신호를 제공하지 못합니다.
둘째, 작은 아키텍처의 용량이 줄어들면서 정확도가 떨어지며, 이를 개선하려면 더 나은 학습 방법이 필요합니다.
이러한 과제를 극복하기 위해 우리는 데이터셋 강화(dataset reinforcement) 방법 [14]에 기반한 새로운 학습 접근법을 개발했습니다. 이 방법은 다음과 같은 두 단계로 이루어집니다:
i) 추가 정보를 사용하여 데이터셋을 한 번 강화하고,
ii) 강화된 데이터셋을 여러 번 실험에 활용합니다.
주어진 계산 자원 내에서 강화된 데이터셋으로 학습하면 원래 데이터셋에 비해 정확도가 향상됩니다.
우리는 효율적인 CLIP 모델 학습을 위해 멀티모달 데이터셋 강화의 변형을 제안합니다.
구체적으로, 이미지-텍스트 DataComp [18] 데이터셋에 강력한 사전 학습된 CLIP 모델 앙상블로부터 생성된 합성 캡션과 임베딩을 추가하여 강화된 데이터셋(DataCompDR)을 생성합니다(그림 3 참조).

DataCompDR로 학습하면 표준 CLIP 학습에 비해 학습 효율성이 크게 향상됩니다.
또한, DataCompDR-1B로 학습하면 이전 연구보다 훨씬 적은 학습 계산 자원을 사용하면서도 여러 평가 지표에서 새로운 최고 성능을 달성합니다(그림 2 참조).
DataCompDR를 활용하여 설계 공간을 탐색한 결과, MobileCLIP이라는 새로운 모바일 친화적인 이미지-텍스트 정렬 인코더 계열을 개발했습니다.
이는 이전 연구들에 비해 더 나은 지연-정확성 균형(latency-accuracy tradeoff)을 제공합니다(그림 1 참조).
우리는 효율적인 이미지 및 텍스트 인코더를 구현하기 위해 구조 재매개화(structural reparametrization) [9–11, 21, 61]와 컨볼루션 토큰 혼합(convolutional token mixing) [62]을 포함한 여러 아키텍처 설계 기법을 활용했습니다.
가장 빠른 변형인 MobileCLIP-S0는 OpenAI의 ViT-B/16 CLIP 모델 [47]보다 약 5배 빠르고, 3배 더 작으면서도 동일한 평균 정확도를 달성합니다.
우리는 모바일 친화적인 CLIP 모델 계열인 MobileCLIP을 설계했습니다.
MobileCLIP의 변형들은 이미지와 텍스트 인코더에서 구조 재매개화(structural reparametrization)를 사용한 하이브리드 CNN-트랜스포머 아키텍처를 채택하여 크기와 지연 시간을 줄였습니다.
우리는 멀티모달 강화 학습(multi-modal reinforced training)이라는 새로운 학습 전략을 도입했습니다.
이 전략은 사전 학습된 이미지 캡셔닝 모델과 강력한 CLIP 모델 앙상블의 지식 전이를 통해 학습 효율성을 향상시킵니다.
MobileCLIP 계열은 제로샷 작업에서 지연-정확성 균형(latency-accuracy tradeoff)에 있어 새로운 최첨단 성능을 달성했으며, ViT-B/16 기반 CLIP 모델에서도 새로운 최고 성능을 기록했습니다.
3. dataset reinforcement
1) 합성 캡션(Synthetic captions)
CLIP 모델을 학습하는 데 사용되는 이미지-텍스트 데이터셋은 대부분 웹에서 수집되며, 이러한 데이터는 본질적으로 잡음(noise)이 많습니다.
DataComp [18] 및 데이터 필터링 네트워크 [16]와 같은 최근 연구들은 광범위한 필터링 메커니즘을 사용하여 웹에서 수집된 데이터셋의 품질을 개선했습니다.
이러한 필터링된 데이터셋은 잡음이 적지만, 캡션이 여전히 충분히 설명적이지 않을 수 있습니다.
캡션의 시각적 설명력(visual descriptiveness)을 강화하기 위해 인기 있는 CoCa [74] 모델을 사용하여 각 이미지 $x_{\text{img}}^{(i)}$에 대해 여러 개의 합성 캡션 $x_{\text{syn}}^{(i,s)}$을 생성합니다(그림 3a 참조).
실제(real) 캡션은 합성 캡션에 비해 일반적으로 더 구체적이지만, 더 많은 잡음을 포함합니다.
우리는 표 3a에서 실제 캡션과 합성 캡션의 조합이 제로샷 검색(zero-shot retrieval) 및 분류 성능(classification performance)을 최적화하는 데 중요하다는 것을 보여줍니다.
2) 이미지 증강(Image augmentations)
각 이미지 $x_{\text{img}}^{(i)}$에 대해 매개변수화된 증강 함수 $A$를 사용하여 여러 개의 증강된 이미지 $x_{\text{img}}^{(i,j)}$를 생성합니다:
$$x_{\text{img}}^{(i,j)} = A(x_{\text{img}}^{(i)}; a^{(i,j)})$$
여기서 $a^{(i,j)}$는 원본 이미지 $x_{\text{img}}^{(i)}$로부터 증강된 이미지 $x_{\text{img}}^{(i,j)}$를 재현하는 데 필요한 증강 매개변수입니다(그림 3a 참조).

데이터셋 증강하는데 원래 이미지에 합성 캡션을 만들어서 여러개 만든다는게 놀랍네
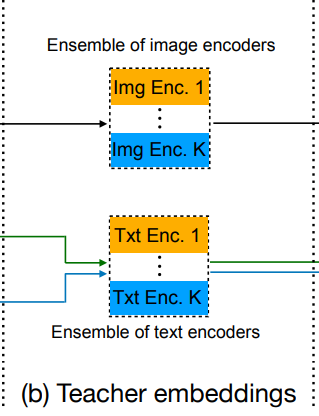
3) 앙상블 교사(Ensemble teacher)
모델 앙상블은 독립적으로 학습된 여러 모델을 결합하여 더 강력한 모델을 만드는 널리 사용되는 기법입니다 [33, 46].
우리는 이 기법을 멀티모달 설정으로 확장하여 K개의 CLIP 모델 앙상블을 강력한 교사 모델로 사용합니다.
이 모델들의 증강된 이미지 $x_{\text{img}}^{(i,j)}$ 와 합성 캡션 $x_{\text{syn}}^{(i,s)}$ 에 대해 피쳐 임베딩을 계산하여 $k$-번째 교사 모델에 대해 $d_k$-차원 벡터 $\psi_{\text{img}}^{(i,j,k)}$ 와 $\psi_{\text{syn}}^{(i,s,k)}$ 를 얻습니다.
또한, 실제 캡션 $x_{\text{txt}}^{(i)}$ 에 대한 교사 임베딩 $\psi_{\text{txt}}^{(i,k)}$ 도 계산합니다(그림 3b 참조).
4) 강화된 데이터셋(Reinforced dataset)
우리는 이미지 증강 매개변수 $a^{(i,j)}$, 합성 캡션 $x_{\text{syn}}^{(i,s)}$, 피쳐 임베딩 $\psi_{\text{img}}^{(i,j,k)}$, $\psi_{\text{syn}}^{(i,s,k)}$, $\psi_{\text{txt}}^{(i,k)}$ 를 CLIP 교사 모델의 추가 지식으로 원본 이미지 $x_{\text{img}}^{(i)}$ 와 캡션 $x_{\text{txt}}^{(i)}$ 와 함께 데이터셋에 저장합니다(그림 3c 참조).
데이터셋 강화는 한 번만 발생하는 비용으로, 여러 효율적인 모델 학습과 실험을 통해 분산되어 활용됩니다.

4. text encoder
CLIP [47] 모델은 비전 트랜스포머와 텍스트 인코딩을 위한 자기-주의(self-attention) 층으로 구성된 고전적인 트랜스포머를 결합했습니다.
이 모델은 효과적이지만, 모바일 배포를 위해서는 더 작고 효율적인 모델이 선호됩니다.
최근 [67]과 같은 연구에서는 합성곱(convolution)이 텍스트 인코딩에서 트랜스포머만큼 효과적일 수 있음을 보여주었습니다.
그러나 우리는 순수하게 합성곱만을 사용하는 아키텍처가 트랜스포머 기반 모델에 비해 성능이 크게 떨어진다는 것을 발견했습니다.
따라서 우리는 텍스트 인코딩을 위한 완전한 합성곱 아키텍처 대신 1-D 합성곱과 자기-주의 층을 결합한 하이브리드 텍스트 인코더를 도입합니다.
하이브리드 텍스트 인코더를 위해, 우리는 학습 시간과 추론 시간 아키텍처를 분리하는 합성곱 토큰 믹서인 Text-RepMixer를 도입합니다.
Text-RepMixer는 [62]에서 소개된 재매개변수화 가능한 합성곱 토큰 믹서(RepMixer)에서 영감을 받았습니다.
추론 시에는 스킵 연결이 재매개변수화됩니다.
아키텍처는 그림 4에 나타나 있습니다.

FeedForward Network (FFN) 블록에서는 선형 계층에 추가적으로 토큰 믹서와 유사한 커널 크기의 깊이별 1-D 합성곱을 결합하여 ConvFFN 블록을 얻습니다.
이 구조는 [20]에서 사용된 합성곱 블록과 유사하지만, 배치 정규화(batchnorm)의 사용과 후속하는 깊이별 1-D 합성곱 층과 결합하여 효율적인 추론을 위한 특징이 다릅니다.
우리의 하이브리드 텍스트 인코더의 최적 설계를 찾기 위해, 우리는 순수한 합성곱 텍스트 인코더를 시작으로, 합성곱 블록을 체계적으로 자기-주의 층으로 교체해 나갔습니다 (표 5 참조).
우리의 모델은 더 작고, 빠르며, ViT-S/16과 같은 효율적인 백본과 결합했을 때 기본 텍스트 인코더보다 비슷한 성능을 얻습니다.
5. image encoder
최근 연구들은 하이브리드 비전 트랜스포머가 좋은 시각적 표현을 학습하는 데 효과적임을 보여주었습니다.
MobileCLIP에서는 최근의 FastViT [62] 아키텍처를 기반으로 한 개선된 하이브리드 비전 트랜스포머인 MCi를 도입합니다.
이 모델에는 아래에서 설명할 몇 가지 중요한 차이점이 있습니다.
FastViT에서는 FFN(FeedForward Network) 블록에 대해 MLP 확장 비율 4.0을 사용합니다.
그러나 최근 연구들 [39, 68]에서는 FFN 블록의 선형 계층에 상당한 중복성이 있음을 밝혔습니다.
이를 개선하기 위해 우리는 단순히 확장 비율을 3.0으로 낮추고 아키텍처의 깊이를 늘렸습니다.
이렇게 함으로써 이미지 인코더의 파라미터 수는 동일하게 유지됩니다.
이 설계는 지연(latency)에 미치는 영향은 최소화하면서도 모델의 용량을 개선하여 다운스트림 작업 성능에 좋은 영향을 미쳤습니다(부록 B 참조).
6. 평가

https://github.com/apple/ml-mobileclip?utm_source=pytorchkr&ref=pytorchkr
GitHub - apple/ml-mobileclip: This repository contains the official implementation of the research paper, "MobileCLIP: Fast Imag
This repository contains the official implementation of the research paper, "MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training" CVPR 2024 - apple/ml-mobileclip
github.com
https://arxiv.org/abs/2311.17049?utm_source=pytorchkr&ref=pytorchkr
MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
Contrastive pretraining of image-text foundation models, such as CLIP, demonstrated excellent zero-shot performance and improved robustness on a wide range of downstream tasks. However, these models utilize large transformer-based encoders with significant
arxiv.org
'AI 논문 > AI trend research' 카테고리의 다른 글
| AI 경량화 - 더 빠르고 저렴한 AI 서비스를 위해(NAVER 강의) (0) | 2025.01.06 |
|---|---|
| 네이버 검색에서 LLM의 활용(LLM으로 학습 데이터를 만드는 사례) (0) | 2025.01.03 |
| Dataset Decomposition: Faster LLM Training with Variable Sequence Length Curriculum (0) | 2024.12.31 |
| 딥마인드의 AlphaDev, 새로운 정렬 알고리즘을 발견하다 (0) | 2023.06.15 |
| TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second (0) | 2022.10.28 |