

1. BERT의 transfer learning
pre-training으로 masked language modeling과 next sentence prediction을 동시에 수행한다.

pre-training한 BERT는 down stream task를 위해 적절하게 초기화된 가중치를 갖고 이를 바탕으로 여러 task를 수행
2. sentence pair classification & single sentence classification
sentence pair classification은 entailment prediction을 생각할 수 있을 것 같고
single sentence classification은 sentiment classification을 생각할 수 있을듯?
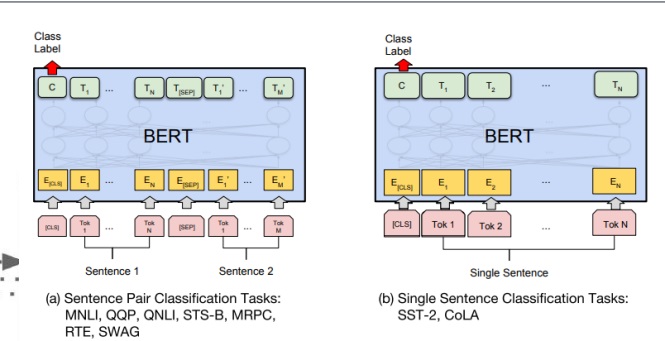
sentence pair classification task와 single sentence classification task에 pre-trained BERT를 활용한 그림
setence pair classification은 2개의 sentence를 <SEP>로 묶어서 하나의 sentence로 만들어서 input으로 준다
<CLS> TOKEN의 최종 embedding vector를 output layer에 집어넣어 label을 예측함
3. single sentence tagging
대표적으로 POS tagging, Named entity Recognition 문제가 있을 것이다.

각 문장의 token들의 최종 encoding vector를 동일한 output layer에 넣으면서 각 token의 정보를 예측하는 문제.
예를 들면 각 단어의 품사나 단어의 개체명 등을 예측
4. BERT와 GPT-1은 무엇이 다른가
4-1) training data size
GPT-1는 BookCorpus의 800M(8억)개의 word를 사용
BERT는 BookCorpus와 wikipedia의 2500M(25억)개의 word를 사용
데이터가 많으면 기본적으로 성능이 좋다.
4-2) special token
GPT-1은 <extract>를 문장의 뒤에 사용하여 down stream task를 수행
BERT는 <CLS>를 문장의 앞에 사용하여 down stream task를 수행하였고 문장의 마지막에 <sep>를 두어 두 문장을 구분하였다.
그리고 segment embedding을 사용하여 token이 어디 문장에 속하는지 정보를 입력으로 주었다.
4-3) batch size
GPT-1이 32000 word, BERT는 128000 word를 사용하였다.
batch size는 보통 크면 클수록 학습이 안정적이고 모델의 성능이 좋다는 것이 알려져있다고????
이거는 좀 의문이 있다. small batch size가 flat minimizer에 도달하여 일반화 성능에 좋다는 것이 실험적으로 밝혀졌다는 것을 배웠다.
https://openreview.net/pdf?id=H1oyRlYgg
근데 이제 그 외에 여러 논문에서 batch size를 꽤 키워도 일반화 성능이 하락하지 않는다는 것을 밝혔다
gradient descent 측면에서 생각해보면 batch size가 크면 계산 속도가 느리지만 안정적으로 최적치를 보장한다. 그러나 지역해에 빠지기도 쉽다.
batch size가 작으면 계산 속도가 빠르지만 안정적으로 최적치를 보장하는 것은 아니다. 그러나 지역해에 빠질 가능성을 줄여준다.
경험적으로는 batch size는 메모리가 허용하는 한 키우면 좋다고 한다.
대규모의 데이터를 학습해야하는 현실적인 측면에서 GPU가 허용하는 한 최대한 키우는 것이 학습시간을 빠르게 한다는 측면에서 효율적이다.
4-4) learning rate
GPT는 모든 fine-tuning 실험에서 동일한 learning rate로 5e-5를 사용하였지만
BERT는 development set에서 최고의 성능을 보인 best task specific fine-tuning learning rate를 사용하였다.
https://arxiv.org/pdf/1810.04805.pdf
4-5) GLUE result
GLUE는 각종 task에 대한 data를 한 곳에 모아놓은 사이트? data set? 정도로 보면 되는데 각 task별 fine-tuning 성능을 보니 BERT가 대부분 성능이 좋았다.

parameter가 더 큰 BERT large모형이 BERT base모형보다 성능이 좋았다는 점도 눈에 띈다.
5. Question Answering
뜻 그대로 단순히 질문에 대한 답을 예측하는 것이 아니라 주어진 지문을 독해하여 잘 이해하고 그 지문에 대한 질문을 하면 답을 예측하는 문제
지문을 잘 이해하여 질문에 필요한 정보를 잘 추출해서 대답을 예측하는 대표적인 NLP task이다.

Daniel과 Sandra가 office로 가고 garden으로 갔다.
Sandra와 John이 kitchen으로 가고 hallway로 갔다.
4명의 등장인물과 4곳의 장소간의 관계를 잘 이해하고 그 중 daniel이 어디에 있냐는 질문에 garden에 갔다는 것을 답으로 제시함.
5-1) SQuAD(Stanford Question Answering Data) 1.1
많은 crawler들이 각종 지문을 수집한 뒤 지문에서 반드시 찾을 수 있는 단어를 답으로 하는 질문을 출제함.
이런 질문에 대한 답을 예측하는 문제

출제자가 여러명이면 답이 여러개일수도 있다고 하는데 일단 정답이 first oil shock라고 해보자.
BERT를 이용한 모델이 leaderboard에서 최상위에 차지하고 있다.

5-2) BERT는 어떻게 SQuAD 문제를 해결할까?
주어진 지문과 질문을 2개의 서로 다른 문장으로 생각하고 <sep> token으로 구분하여 1개의 input을 만든다.
BERT의 최종 encoding vector로 각 지문의 단어별 encoding vector를 얻을 수 있다.
질문의 답이 반드시 지문 내 단어로 주어진다는 사실에 기반하여 문구의 start index와 final index를 예측하는 output layer를 생성함.
지문의 단어가 124개라고하면 최종 word encoding vector도 124개이고 각각을 output layer에 넣어 vector하나당 하나의 scalar을 뽑는다고 하자.
124개의 scalar를 softmax를 취하면 확률분포가 된다.
ground truth를 알기때문에 start index에 가장 높은 확률이 되도록 softmax loss를 최소화하는 방향으로 학습한다.
또 하나의 output layer를 만들어 동일하게 124개의 scalar을 얻고 softmax를 취하여 final index의 확률이 가장 높도록 학습을 진행한다.

5-3) SQuAD 2.0
이번에는 지문에 질문의 답이 없는 경우도 포함시켰다. <CLS> token을 활용하여 지문을 모두 이해한 뒤 답이 있는지 없는지 예측한다.

답이 없으면 no answer로 내면 끝이지만 답이 있으면 지문의 단어 벡터를 이용하여 위에서 수행한 SQuAD 1.1의 start index, final index를 예측하는 model을 수행한다.
답이 있으면 지문에 있긴하다라는 말인가보네

6. SWAG 문제
주어진 문장의 다음에 나올 적절한 문장을 4개의 문장 중에서 고르는 문제

BERT로부터 주어진 문장과 1번 문장을 하나로 만들어 <CLS>의 encoding vector를 구하고
주어진 문장과 2번 문장을 하나로 만들어 <CLS>의 encoding vector를 만들고…
반복해서 총 4개의 encoding vector를 얻는다.
각각을 scalar로 만들어주는 동일한 output layer에 넣고 softmax를 넣으면 4개의 문장에 대한 확률분포가 나온다.
1번이 정답이라면 1번의 확률이 가장 높도록 학습을 진행하면 된다.

7. BERT ablation study
7-1) ablation study란?
https://cumulu-s.tistory.com/8
Ablation study란 무엇인가?
논문을 읽던 중, ablation study 라고 하는 단어를 종종 마주할 수 있었다. 따로 논문에 이게 어떤 것인지에 대해서 설명이 없어서, 이에 대해서 정리해보고자 한다. In the context of deep learning, what is an.
cumulu-s.tistory.com
Ablation Study는 장기, 조직, 혹은 살아있는 유기체의 어떤 부분을 수술적인 제거 후에 이것이 없을때 해당 유기체의 행동을 관찰하는 것을 통해서 장기, 조직, 혹은 살아있는 유기체의 어떤 부분의 역할이나 기능을 실험해보는 방법
"machine learning system의 building blocks을 제거해서 전체 성능에 미치는 효과에 대한 insight를 얻기 위한 과학적 실험"
더 나아가서 제안한 요소가 모델에 어떠한 영향을 미치는지 확인하고 싶을 때, 이 요소를 포함한 모델과 포함하지 않은 모델을 비교하는 것을 말한다.
이는 딥러닝 연구에서 매우 중요한 의미를 지니는데, 시스템의 인과관계(causality)를 알아보는데 중요한 의미를 가지기 때문이다.
7-2) BERT 연구자들이 말하는 ablation study
layer parameter, model size를 GPU resource가 허락하는 한 점점 늘리면서 학습을 진행했더니 모델의 성능이 끝을 모르고 증가했다.(not asymptotic)
가능하면 pre-train후 최대한 layer가 deep한 fine-tuning model을 사용하면 끝을 모르는 성능 향상을 기대할 수 있다는 가능성 제시

그래프에서 보면 parameter수가 늘어날수록 model 성능은 끝을 모르고 점점 증가한다
'딥러닝 > NLP' 카테고리의 다른 글
| BERT를 가볍게 만드려는 시도 - ALBERT 모델 공부하기 (0) | 2022.10.27 |
|---|---|
| GAN의 원리에 착안한 ELECTRA와 학습하지 않아도 응용을 잘하는 GPT-3 (0) | 2022.10.26 |
| 현대 NLP 모델의 근간이 되는 BERT의 기본적인 특징 (0) | 2022.10.24 |
| 괴물 언어모델 GPT-1에서 더 강력해진 GPT-2 파헤치기 (0) | 2022.10.21 |
| NLP의 transfer learning 기본 개념(zero shot, one shot, few shot) 익히기 (0) | 2022.10.20 |