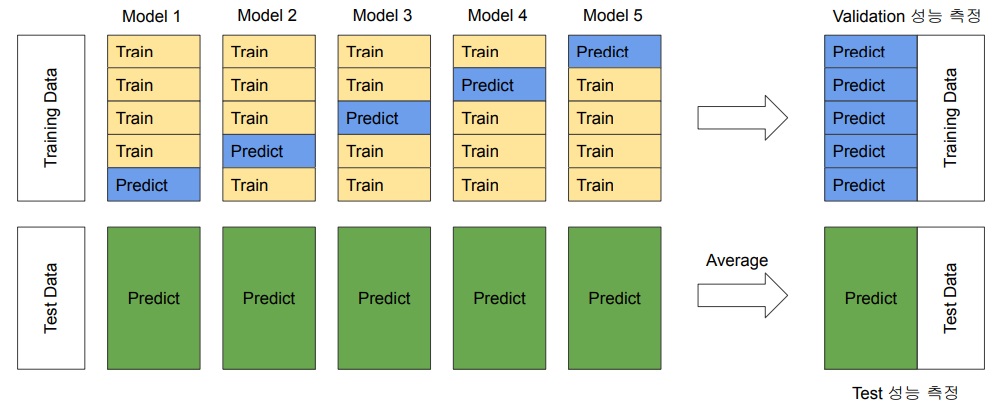
cross validation out of fold prediction
model training시 cross validation을 통해서 model의 fold를 여러개 나눠서 out of fold validation 성능을 측정하고 test data예측을 통해 성능 향상을 유도
대충 데이터가 다음과 같이 생겼는데

2009/12~2011/11까지 데이터가 존재하고 우리가 예측해야할 것은 2011/12
train data는 2009/12~2011/11이고 test data는 2011/12
1) 2009/12~2011/11에서 적절하게 train과 validation을 label별로 고른 비율을 가지도록 stratified k fold split함
2) 각 fold별로 validation 예측을 하고 예측한 것을 out of fold에 하나 하나 다 모으는 거
3) 그리고 각 fold에서 만든 모델을 test data에 대해 prediction을 함
4) fold를 다 돌면 out of fold에 모인 것은 사실 결국에는 전체 train data에 대한 예측치가 다 모여서
train data 정답과 비교해서 out of fold validation 성능 계산 가능
5) 각 fold에서 예측한 test prediction을 모두 모아 ensemble를 하여 최종 test prediction으로 사용함
ensemble에 soft voting이나 hard voting을 사용할 수 있지 않을까
아무튼 이렇게 하면 test data를 제출하기전에 미리 성능을 어느정도 예측해볼 수 있다는거임
*기타
경험상 실제 테스트 성능과 꽤 비슷해짐
+ class unbalance일때 stratified k - fold training을 하면 효과가 있을 수 있다고 알려져있다
+ 정형데이터 뿐만 아니라 비정형데이터의 딥러닝에서도 사용하는 경우 종종 있다
예시 코드
def make_lgb_oof_prediction(train, y, test, features, categorical_features='auto', model_params=None, folds=10,threshold=0.60):
x_train = train[features]
x_test = test[features]
# 테스트 데이터 예측값을 저장할 변수
test_preds = np.zeros(x_test.shape[0])
# Out Of Fold Validation 예측 데이터를 저장할 변수
y_oof = np.zeros(x_train.shape[0])
# 폴드별 평균 Validation 스코어를 저장할 변수
score = 0
# 피처 중요도를 저장할 데이터 프레임 선언
fi = pd.DataFrame()
fi['feature'] = features
# Stratified K Fold 선언
skf = StratifiedKFold(n_splits=folds, shuffle=True, random_state=SEED)
for fold, (tr_idx, val_idx) in enumerate(skf.split(x_train, y)):
# train index, validation index로 train 데이터를 나눔
x_tr, x_val = x_train.loc[tr_idx, features], x_train.loc[val_idx, features]
y_tr, y_val = y[tr_idx], y[val_idx]
print(f'fold: {fold+1}, x_tr.shape: {x_tr.shape}, x_val.shape: {x_val.shape}')
# LightGBM 데이터셋 선언
dtrain = lgb.Dataset(x_tr, label=y_tr)
dvalid = lgb.Dataset(x_val, label=y_val)
# LightGBM 모델 훈련
clf = lgb.train(
model_params,
dtrain,
valid_sets=[dtrain, dvalid], # Validation 성능을 측정할 수 있도록 설정
feval = lgb_f1_score,
categorical_feature=categorical_features,
)
# Validation 데이터 예측
val_preds = clf.predict(x_val)
# Validation index에 예측값 저장
y_oof[val_idx] = (val_preds >= threshold).astype(int)
# 폴드별 Validation 스코어 측정
print(f"Fold {fold + 1} | F1: {f1_score(y_val, (val_preds >= threshold).astype(int),average='macro',zero_division=0)}")
print('-'*80)
# score 변수에 폴드별 평균 Validation 스코어 저장
score += f1_score(y_val, (val_preds >= threshold).astype(int),average='macro',zero_division=0) / folds
# 테스트 데이터 예측하고 평균해서 저장
test_preds += clf.predict(x_test) / folds
# 폴드별 피처 중요도 저장
fi[f'fold_{fold+1}'] = clf.feature_importance()
del x_tr, x_val, y_tr, y_val
#gc.collect()
print(f"\nMean f1 = {score}") # 폴드별 Validation 스코어 출력
print(f"OOF f1 = {f1_score(y, y_oof,average='macro',zero_division=0)}") # Out Of Fold Validation 스코어 출력
# 폴드별 피처 중요도 평균값 계산해서 저장
fi_cols = [col for col in fi.columns if 'fold_' in col]
fi['importance'] = fi[fi_cols].mean(axis=1)
return y_oof, test_preds, fi